- ホーム
- Microsoft
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- Microsoft.DP-100.v2024-11-16.q151
- 質問35
有効的なDP-100問題集はJPNTest.com提供され、DP-100試験に合格することに役に立ちます!JPNTest.comは今最新DP-100試験問題集を提供します。JPNTest.com DP-100試験問題集はもう更新されました。ここでDP-100問題集のテストエンジンを手に入れます。
DP-100問題集最新版のアクセス
「528問、30% ディスカウント、特別な割引コード:JPNshiken」
パフォーマンス曲線の図に示されているように、広告応答モデルに新しいコスト係数シナリオを実装する必要があります。
どのテクニックを使うべきでしょうか?
どのテクニックを使うべきでしょうか?
正解:A
シナリオ:
現在のコスト要因シナリオと提案されたコスト要因シナリオのパフォーマンス曲線を次の図に示します。

広告傾向モデルではカットしきい値は0.45で、加重カッパが0.1から外れると再トレーニングが行われます。
+/- 5% です。
モデルを開発する
テストレット2
ケーススタディ
概要
あなたは、米国の質の高い個人および商業用不動産を専門とする企業、Fabrikam Residences のデータ サイエンティストです。Fabrikam Residences はヨーロッパへの進出を検討しており、ヨーロッパの主要都市の個人住宅の価格を調査するよう依頼されました。Azure Machine Learning Studio を使用して、不動産の中央値を測定します。線形回帰モジュールとベイジアン線形回帰モジュールを使用して、不動産価格を予測する回帰モデルを作成します。
データセット
ロンドンとパリの 2 つの都市の不動産詳細を含む CSV 形式のデータセットが 2 つあり、次の列があります。
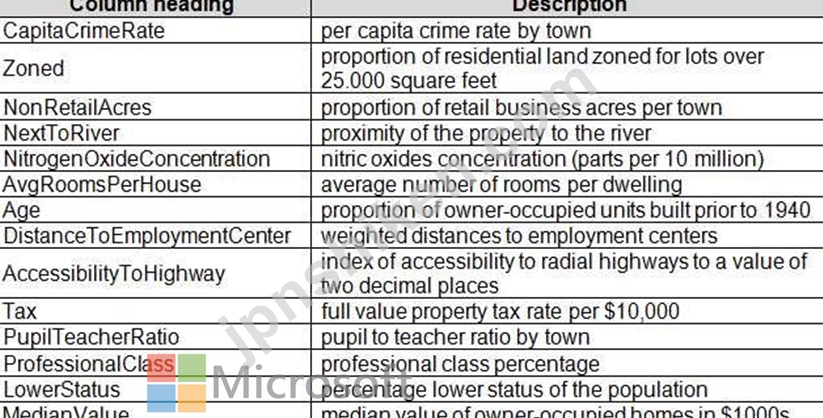
2 つのデータセットは、Azure Machine Learning Studio に個別のデータセットとして追加され、実験の開始点として組み込まれています。
データセットの問題
両方のデータセットの AccessibilityToHighway 列には欠損値が含まれています。欠損値を埋める前に、データ内の他の変数を使用して条件付きでモデル化できるように、欠損データを新しいデータに置き換える必要があります。
各データセットの列には欠損値と null 値が含まれています。データセットには多くの外れ値も含まれています。Age 列には外れ値の割合が高くなっています。Age 列に外れ値がある行を削除する必要があります。
MedianValue 列と AvgRoomsinHouse 列はどちらも数値形式でデータを保持します。2 つの列の関係をより詳細に分析するには、特徴選択アルゴリズムを選択する必要があります。
モデルの適合
モデルは過剰適合の兆候を示しています。過剰適合を軽減する、より洗練された回帰モデルを作成する必要があります。
実験要件
パフォーマンスを評価するには、線形回帰モジュールとベイズ線形回帰モジュールを相互検証する実験を設定する必要があります。
いずれの場合も、データセットの予測子は MedianValue という列です。最初の調査で、データセットは MedianValue 列を除いて構造が同一であることがわかりました。小さい方のパリのデータセットにはテキスト形式の MedianValue が含まれていますが、大きい方のロンドンのデータセットには数値形式の MedianValue が含まれています。パリのデータセットの MedianValue 列のデータ型がロンドンのデータセットの構造と一致していることを確認する必要があります。
結果を予測するには、データの列に優先順位を付ける必要があります。関係性を測定するには、非パラメータ統計を使用する必要があります。
MedianValue 列と AvgRoomsinHouse 列の関係を分析するには、特徴選択アルゴリズムを使用する必要があります。
モデルのトレーニング
トレーニング済みのモデルとテスト データセットが与えられた場合、特徴変数の順列特徴重要度スコアを計算する必要があります。モデルの精度を調査し、結果を再現するには、正しいメトリックを選択するように順列特徴重要度モジュールを設定する必要があります。
ハイパーパラメータを使用して学習フェーズを高速化するには、モデル学習プロセスでハイパーパラメータを構成する必要があります。さらに、この構成では、各評価間隔で最もパフォーマンスの低い実行をキャンセルし、成功する可能性の高いモデルに労力とリソースを集中させる必要があります。
モデルがハイパーパラメータの調整でコンピューティング リソースを効率的に使用しない可能性があることを懸念しています。また、モデルが全体的な調整時間の増加を阻止する可能性があることも懸念しています。したがって、有望なジョブを終了せずに節約できる早期停止基準をモデルに実装する必要があります。
テスト
Azure Machine Learning Studio のパーティションとサンプル モジュールを使用して、サンプリングに基づいてデータセットの複数のパーティションを作成する必要があります。クロス検証用に 3 つの等しいパーティションを作成する必要があります。また、テスト データセットとトレーニング データセットの行が各都市の主要な川の近くにある物件ごとに均等に分割されるように、クロス検証プロセスを構成する必要があります。物件が川の近くにあることを識別するデータは、NextToRiver という列に保持されます。データがサンプリング プロセスを通過する前に、このタスクを完了する必要があります。
大都市の不動産価格データを示す不動産データセットを使用して線形回帰モジュールをトレーニングする場合、モデルで使用する最適な特徴を決定する必要があります。特徴の重要度プロセスの完了前と完了後にパフォーマンスを測定するために提供されている標準メトリックを選択できます。複数のトレーニング モデル間で特徴の分布が一貫していることを確認する必要があります。
データの視覚化
テスト結果を Fabrikam Residences チームに提供する必要があります。結果の提示に役立つデータ視覚化を作成します。
モデルの診断テスト評価を実行するには、受信者動作特性 (ROC) 曲線を作成する必要があります。Two-Class Decision Forest モジュールと Two-Class Decision Jungle モジュールを相互に比較するには、Azure Machine Learning Studio で ROC 曲線を作成するための適切な方法を選択する必要があります。
モデルを開発する
質問セット3
現在のコスト要因シナリオと提案されたコスト要因シナリオのパフォーマンス曲線を次の図に示します。
広告傾向モデルではカットしきい値は0.45で、加重カッパが0.1から外れると再トレーニングが行われます。
+/- 5% です。
モデルを開発する
テストレット2
ケーススタディ
概要
あなたは、米国の質の高い個人および商業用不動産を専門とする企業、Fabrikam Residences のデータ サイエンティストです。Fabrikam Residences はヨーロッパへの進出を検討しており、ヨーロッパの主要都市の個人住宅の価格を調査するよう依頼されました。Azure Machine Learning Studio を使用して、不動産の中央値を測定します。線形回帰モジュールとベイジアン線形回帰モジュールを使用して、不動産価格を予測する回帰モデルを作成します。
データセット
ロンドンとパリの 2 つの都市の不動産詳細を含む CSV 形式のデータセットが 2 つあり、次の列があります。
2 つのデータセットは、Azure Machine Learning Studio に個別のデータセットとして追加され、実験の開始点として組み込まれています。
データセットの問題
両方のデータセットの AccessibilityToHighway 列には欠損値が含まれています。欠損値を埋める前に、データ内の他の変数を使用して条件付きでモデル化できるように、欠損データを新しいデータに置き換える必要があります。
各データセットの列には欠損値と null 値が含まれています。データセットには多くの外れ値も含まれています。Age 列には外れ値の割合が高くなっています。Age 列に外れ値がある行を削除する必要があります。
MedianValue 列と AvgRoomsinHouse 列はどちらも数値形式でデータを保持します。2 つの列の関係をより詳細に分析するには、特徴選択アルゴリズムを選択する必要があります。
モデルの適合
モデルは過剰適合の兆候を示しています。過剰適合を軽減する、より洗練された回帰モデルを作成する必要があります。
実験要件
パフォーマンスを評価するには、線形回帰モジュールとベイズ線形回帰モジュールを相互検証する実験を設定する必要があります。
いずれの場合も、データセットの予測子は MedianValue という列です。最初の調査で、データセットは MedianValue 列を除いて構造が同一であることがわかりました。小さい方のパリのデータセットにはテキスト形式の MedianValue が含まれていますが、大きい方のロンドンのデータセットには数値形式の MedianValue が含まれています。パリのデータセットの MedianValue 列のデータ型がロンドンのデータセットの構造と一致していることを確認する必要があります。
結果を予測するには、データの列に優先順位を付ける必要があります。関係性を測定するには、非パラメータ統計を使用する必要があります。
MedianValue 列と AvgRoomsinHouse 列の関係を分析するには、特徴選択アルゴリズムを使用する必要があります。
モデルのトレーニング
トレーニング済みのモデルとテスト データセットが与えられた場合、特徴変数の順列特徴重要度スコアを計算する必要があります。モデルの精度を調査し、結果を再現するには、正しいメトリックを選択するように順列特徴重要度モジュールを設定する必要があります。
ハイパーパラメータを使用して学習フェーズを高速化するには、モデル学習プロセスでハイパーパラメータを構成する必要があります。さらに、この構成では、各評価間隔で最もパフォーマンスの低い実行をキャンセルし、成功する可能性の高いモデルに労力とリソースを集中させる必要があります。
モデルがハイパーパラメータの調整でコンピューティング リソースを効率的に使用しない可能性があることを懸念しています。また、モデルが全体的な調整時間の増加を阻止する可能性があることも懸念しています。したがって、有望なジョブを終了せずに節約できる早期停止基準をモデルに実装する必要があります。
テスト
Azure Machine Learning Studio のパーティションとサンプル モジュールを使用して、サンプリングに基づいてデータセットの複数のパーティションを作成する必要があります。クロス検証用に 3 つの等しいパーティションを作成する必要があります。また、テスト データセットとトレーニング データセットの行が各都市の主要な川の近くにある物件ごとに均等に分割されるように、クロス検証プロセスを構成する必要があります。物件が川の近くにあることを識別するデータは、NextToRiver という列に保持されます。データがサンプリング プロセスを通過する前に、このタスクを完了する必要があります。
大都市の不動産価格データを示す不動産データセットを使用して線形回帰モジュールをトレーニングする場合、モデルで使用する最適な特徴を決定する必要があります。特徴の重要度プロセスの完了前と完了後にパフォーマンスを測定するために提供されている標準メトリックを選択できます。複数のトレーニング モデル間で特徴の分布が一貫していることを確認する必要があります。
データの視覚化
テスト結果を Fabrikam Residences チームに提供する必要があります。結果の提示に役立つデータ視覚化を作成します。
モデルの診断テスト評価を実行するには、受信者動作特性 (ROC) 曲線を作成する必要があります。Two-Class Decision Forest モジュールと Two-Class Decision Jungle モジュールを相互に比較するには、Azure Machine Learning Studio で ROC 曲線を作成するための適切な方法を選択する必要があります。
モデルを開発する
質問セット3

- 質問一覧「151問」
- 質問1 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問2 Azure Machine Learning ワークスペースに保存されているデータ...
- 質問3 ある都市の住宅販売データを含むデータセットがあります。データ
- 質問4 Azure Machine Learning ワークスペースを使用しています。モデ...
- 質問5 次の形式の salesData という名前の Python データ フレームがあ...
- 質問6 Azure Machine Learning プロジェクト ファイルを含む既存の Git...
- 1コメント質問7 提供されたトレーニング セットを使用してバイナリ分類モデルを
- 質問8 Azure Machine Learning ワークスペースを作成します。ワークス...
- 質問9 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問10 テスト要件に応じてデータを分割する方法を特定する必要がありま
- 質問11 Azure Machine Learning ワークスペースを作成します。 DataDrif...
- 1コメント質問12 画像分類用のディープラーニング畳み込みニューラル ネットワー
- 質問13 Python SDK v2 を使用して、workspace1 という名前の Azure Mach...
- 質問14 英語のテキストをフランス語のテキストに翻訳するための機械学習
- 質問15 テスト要件に応じてデータを分割する方法を特定する必要がありま
- 質問16 Azure Machine Learning Studio を使用して実験を作成しています...
- 質問17 データの視覚化要件に従って、診断テスト評価の視覚化を作成する
- 質問18 computet という名前のコンピューティング インスタンスを使用し...
- 質問19 短い文章形式で書かれた 12,000 件の顧客レビューを含む CSV フ...
- 質問20 PyTorch フレームワークを使用して、マルチクラス画像分類ディー...
- 質問21 Python で機械学習モデルを作成しています。提供されたデータセ...
- 1コメント質問22 バイナリ分類モデルを作成します。 モデルのパフォーマンスを評
- 質問23 あなたのチームはデータ エンジニアリングとデータ サイエンスの...
- 1コメント質問24 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問25 ビジネス アプリケーションで使用されるバッチ推論パイプライン
- 1コメント質問26 モデルのトレーニング要件に応じて早期停止基準を実装する必要が
- 質問27 Azure Machine Learning プロジェクト ファイルを含む既存の Git...
- 質問28 STANDARD_D1 仮想マシン イメージを使用して、ComputeOne という...
- 質問29 Azure ストレージ アカウント内の BLOB コンテナーを参照する、t...
- 質問30 ある都市の住宅販売データを含むデータセットがあります。データ
- 質問31 バイアスと分散の問題に対処するには、グローバル ペナルティ イ...
- 質問32 x.1、x2、x3 機能に対して scikit-learn Python ライブラリを使...
- 質問33 Azure を使用して機械学習の実験を開発しています。次の画像は、...
- 質問34 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 1コメント質問35 パフォーマンス曲線の図に示されているように、広告応答モデルに
- 1コメント質問36 2 つの異なる年齢グループ内で糖尿病の陽性症例を予測するバイナ...
- 質問37 Azure Machine Learning Service を使用して、ニューラル ネット...
- 質問38 データの視覚化要件に従って、診断テスト評価の視覚化を作成する
- 質問39 Azure Container Instance にモデルをデプロイします。 モデル A...
- 質問40 トレーニング クラスターと推論クラスターを含む Azure Machine ...
- 質問41 STANDARD_D1 仮想マシン イメージを使用して、ComputeOne という...
- 質問42 Azure Machine Learning Studio で分類タスクを実行しています。...
- 質問43 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問44 Azure Databricks ワークスペースとリンクされた Azure Machine ...
- 質問45 Azure Machine Learning Studio で分類タスクを実行しています。...
- 質問46 Workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問47 ローカル機械学習パイプラインのパフォーマンス問題を解決する必
- 質問48 TensorFlow を使用してディープ ラーニング モデルを開発してい...
- 質問49 さまざまな都市の住宅所有に関する人口統計データを調査する予定
- 質問50 Azure Machine Learning Studio を使用してバイナリ分類モデルを...
- 質問51 Azure Machine Learning ワークスペースを作成します。 次の要件...
- 質問52 猫と犬を識別するためのディープラーニング モデルを作成してい
- 質問53 Azure Machine Learning で実験としてスクリプトを実行するには...
- 質問54 グローバル ペナルティ検出モデルのサンプリング戦略を構築する
- 質問55 分類タスクに取り組んでいます。生徒がサッカーをしたいかどうか
- 質問56 Python SDK v2 を使用して Azure Machine Learning ワークスペー...
- 質問57 完成したバイナリ分類マシンを評価しています。 評価基準として
- 質問58 モデルのトレーニング要件に応じて、順列特徴重要度モジュールを
- 質問59 次のバージョンのモデルを登録します。 (Exhibit) Azure ML Pyth...
- 質問60 クリーニングが必要な生のデータセットを分析しています。 Azure...
- 質問61 ある都市の住宅販売データを含むデータセットがあります。データ
- 質問62 Azure Machine Learning ワークスペースを作成し、MLflow ライブ...
- 質問63 あなたはワイナリーでデータ サイエンティストとして雇用されて
- 質問64 Azure Machine Learning Studio で実験を作成します。10,000 行...
- 質問65 猫と犬を識別するためのディープラーニング モデルを作成してい
- 質問66 Azure Machine Learning Studio を使用して実験を作成しています...
- 質問67 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問68 バイオメディカル研究会社は、実験的な医療治療試験に人々を登録
- 質問69 グローバル ペナルティ検出モデルのサンプリング戦略を構築する
- 質問70 Azure Machine Learning Studio を使用してバイナリ分類モデルを...
- 質問71 実験の要件とデータセットに基づいて、特徴ベースの特徴選択モジ
- 1コメント質問72 Azure Machine Learning の Hyperdrive 機能を使用して、モデル...
- 質問73 train.py という名前の Python スクリプトを作成し、scripts と...
- 1コメント質問74 Azure Machine Learning Python SDK を使用してバッチ推論パイプ...
- 1コメント質問75 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問76 あなたは銀行に勤務するデータ サイエンティストであり、Azure M...
- 質問77 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問78 ある組織は Azure Machine Learning サービスを使用しており、機...
- 質問79 Aunt Machine Learning を使用して機械学習モデルをトレーニング...
- 質問80 ローカルペナルティ検出データに対してスケーリング戦略を実装す
- 質問81 外れ値を削除する前に、年齢列に外れ値が存在するかどうかを視覚
- 質問82 次のように定義された 6 つのデータ ポイントを含む Python NumP...
- 質問83 人が病気にかかっているかどうかを予測するためのバイナリ分類モ
- 質問84 群衆感情モデルの評価戦略を定義する必要があります。 どの 3 つ...
- 質問85 モデルの適合の問題を修正する必要があります。 どの 3 つのアク...
- 質問86 Azure Machine Learning Studio を使用して、2 つのデータ セッ...
- 質問87 Azure Machine Learning Studio の 2 クラス ニューラル ネット...
- 質問88 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 1コメント質問89 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問90 テスト要件に応じてデータを分割する方法を特定する必要がありま
- 質問91 Azure Machine Learning を使用してモデルをトレーニングします...
- 質問92 Azure Machine Learning を使用して機械学習モデルを作成します...
- 1コメント質問93 特徴抽出方法を選択する必要があります。 どちらの方法を使用す
- 1コメント質問94 Azure Machine Learning Designer を使用して、次のデータセット...
- 質問95 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問96 Azure Machine Learning SDK for Python を使用して、Azure Mach...
- 質問97 Azure Machine Learning Python SDK v2 のハイパーパラメータ調...
- 質問98 Azure Machine Learning ワークスペースを管理します。Azure Mac...
- 質問99 Azure Machine Learning サービスを使用して、training.data と...
- 質問100 Azure Machine Learning ワークスペースを作成します。 実験用の...
- 質問101 Azure Machine Learning Studio で実験を作成します。10,000 行...
- 1コメント質問102 分類モデルをトレーニングするデータを含むコンマ区切り値 (CSV)...
- 質問103 Azure Machine Learning ワークスペースを管理します。model1 と...
- 質問104 ローカル機械学習パイプラインのパフォーマンス問題を解決する必
- 質問105 決定木アルゴリズムを使用して分類モデルをトレーニングします。
- 質問106 Azure Machine Learning ワークスペースを使用しています。モデ...
- 質問107 Azure Machine Learning ワークスペースがあります。ワークスペ...
- 質問108 モデルのトレーニング要件に応じて早期停止基準を実装する必要が
- 質問109 次の形式の salesData という名前の Python データ フレームがあ...
- 質問110 ある組織は Azure Machine Learning サービスを使用しており、機...
- 質問111 次の形式の salesData という名前の Python データ フレームがあ...
- 1コメント質問112 機械学習モデルを作成しています。null 行を含むデータセットが...
- 質問113 短い文章形式で書かれた 12,000 件の顧客レビューを含む CSV フ...
- 質問114 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問115 Azure Machine Learning デザイナーを使用して実験を構築してい...
- 質問116 機械学習モデルをトレーニングして登録します。モデルを使用して
- 質問117 Azure Machine Learning ワークスペースから実行される実験を取...
- 質問118 Azure Machine Learning を使用して、dataset1 という名前のデー...
- 質問119 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問120 Azure Machine Learning Studio で線形回帰モデルを開発していま...
- 質問121 トレーニング クラスターと推論クラスターを含む Azure Machine ...
- 質問122 (Exhibit) ワークスペース内のデータや実験を操作するには、Azur...
- 質問123 ワークスペース内のデータや実験を操作するには、Azure Machine ...
- 質問124 特徴抽出方法を選択する必要があります。 どちらの方法を使用す
- 質問125 決定木アルゴリズムを使用しています。ツリーの深さが 10 で適切...
- 質問126 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問127 2,000 行を含むデータセットがあります。Azure Learning Studio ...
- 質問128 モデルの適合の問題を修正する必要があります。 どの 3 つのアク...
- 質問129 スペースを確保し、開発環境をセットアップします。Tensorflow ...
- 質問130 モデルの適合の問題を修正する必要があります。 どの 3 つのアク...
- 質問131 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問132 ローカルペナルティ検出データに対してスケーリング戦略を実装す
- 質問133 Azure Machine Learning デザイナーを使用してトレーニング パイ...
- 質問134 Azure Machine Learning Service を使用して、ニューラル ネット...
- 質問135 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問136 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問137 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問138 群衆感情モデルの評価戦略を定義する必要があります。 どの 3 つ...
- 質問139 パフォーマンス曲線の図に示されているように、広告応答モデルに
- 質問140 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問141 Azure Machine Learning を使用してモデルをトレーニングします...
- 質問142 統計分布の非対称性を分析しています。 次の画像には、2 つのデ...
- 質問143 Azure Container Instance にモデルをデプロイします。 モデル A...
- 質問144 Azure Machine Learning デザイナーを使用してトレーニング パイ...
- 質問145 Azure Machine Learning Studio で多重線形回帰モデルを作成して...
- 質問146 次のコードがあります。このコードは、スクリプトを実行するため
- 1コメント質問147 Azure Machine Learning SDK を使用して、分類モデルをトレーニ...
- 質問148 Azure Machine Learning ワークスペースには、real_estate_dat a...
- 質問149 Azure Machine Learning ワークスペースがあります。 ワークスペ...
- 質問150 Azure Machine Learning ワークスペースを作成します。 DataDrif...
- 質問151 2,000 行を含むデータセットがあります。Azure Learning Studio ...

最新のコメント (最新のコメントはトップにあります。)
しきい値0.2が正解では