- ホーム
- Microsoft
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- Microsoft.DP-100.v2023-06-06.q262
- 質問34
有効的なDP-100問題集はJPNTest.com提供され、DP-100試験に合格することに役に立ちます!JPNTest.comは今最新DP-100試験問題集を提供します。JPNTest.com DP-100試験問題集はもう更新されました。ここでDP-100問題集のテストエンジンを手に入れます。
DP-100問題集最新版のアクセス
「528問、30% ディスカウント、特別な割引コード:JPNshiken」
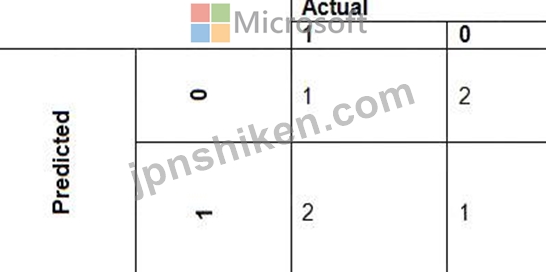
ローカル ペナルティ検出データのスケーリング戦略を実装する必要があります。
どの正規化タイプを使用する必要がありますか?
どの正規化タイプを使用する必要がありますか?
正解:C
説明
ポスト バッチ正規化統計 (PBN) は、推論元の論文で使用できるバッチ正規化の母平均と分散を評価する方法の Microsoft Cognitive Toolkit (CNTK) バージョンです。
CNTK では、カスタム ネットワークは BrainScriptNetworkBuilder を使用して定義され、CNTK ネットワーク記述言語「BrainScript」で記述されます。シナリオ:
ローカル ペナルティ検出モデルは、BrainScript を使用して作成する必要があります。
参考文献:
https://docs.microsoft.com/en-us/cognitive-toolkit/post-batch-normalization-statistics
トピック 1、ケース スタディ 1
概要
あなたは、プロのスポーツ イベントにデータ サイエンスを提供する会社のデータ サイエンティストです。モデルは、次のビジネス目標を達成するためのグローバルおよびローカル市場データになります。
*群衆の反応からの音声に基づいて、スポーツ イベントでのモバイル デバイス ユーザーの感情を理解します。
*広告に反応するユーザーの傾向にアクセスします。
*モバイル デバイスに配信される広告のスタイルをカスタマイズします。
*ビデオを使用して、ペナルティ イベントを検出します。
現在の環境
要件
* ペナルティ イベントの検出に使用されるメディアは、コンシューマ デバイスによって提供されます。メディアには、スポーツ イベント中に撮影され、ソーシャル メディアを使用して騙された画像や動画が含まれる場合があります。画像と動画のサイズと形式はさまざまです。
* モデル作成に使用できるデータは、7 年間のスポーツ イベント メディアで構成されています。スポーツ イベント メディアには、記録されたビデオ、ラジオ解説の書き起こし、関連するソーシャル メディア フィードからのログ、スポーツ イベント中にキャプチャされたフィードが含まれます。
*観衆の感情には、モノとステレオの両方の形式でイベント参加者から提出されたオーディオ録音が含まれます。
広告
* 広告応答モデルは、各イベントの開始時にトレーニングし、スポーツ イベント中に適用する必要があります。
* 市場セグメンテーション nxxlels は、同様の広告 resporr.r 履歴を最適化する必要があります。
* サンプリングは、同じ機能を共有するローカルおよびグローバル セグメンテーション モデルの相互および集合的排他性を保証する必要があります。
* ユーザーが広告に反応する傾向を判断する前に、ローカル市場セグメンテーション モデルが適用されます。
* データ サイエンティストは、モデルの劣化と崩壊を検出できなければなりません。
* 広告応答モデルは、非線形境界機能をサポートする必要があります。
* 広告傾向モデルではカットしきい値が 0.45 であり、加重カッパが 0.1 から逸脱すると再トレーニングが発生します
+/-5%。
* 広告傾向モデルは、次の図に示すコスト要因を使用します。
広告傾向モデルは、次の図に示す提案されたコスト ファクターを使用します。

現在および提案されているコスト要因シナリオのパフォーマンス曲線は、次の図に示されています。

ペナルティの検出とセンチメント
所見
*データ サイエンティストは、ペナルティ イベントの検出に複数の機械学習モデルを使用して、インテリジェントなソリューションを構築する必要があります。
*データ サイエンティストは、機械学習パイプラインで自動機能エンジニアリングとモデル構築を使用して、ローカル環境でノートブックを構築する必要があります。
*動的ワーカー割り当てを使用して Spark インスタンスを使用して再トレーニングするには、ノートブックをデプロイする必要があります
*ノートブックは、データのソースのみを再コード化するために、新しい Spark インスタンスで同じコードを使用して実行する必要があります。
*グローバル ペナルティ検出モデルは、トレーニング中に動的ランタイム グラフ計算を使用してトレーニングする必要があります。
*ローカル ペナルティ検出モデルは、BrainScript を使用して作成する必要があります。
* ローカル群衆センチメント モデルの実験では、ローカル ペナルティ検出データを組み合わせる必要があります。
* 群衆感情モデルは、歓声や既知のキャッチ フレーズなどの既知の音を識別しなければなりません。個々の群衆感情モデルは、同様の音を検出します。
* ローカル モデルの共有機能はすべて連続変数です。
* 共有機能は倍精度を使用する必要があります。後続のレイヤーには、総移動平均と標準偏差メトリックが使用可能である必要があります。
セグメント
本番環境の最初の数週間で、次のことが観察されました。
※広告の反応率が低下。
*ドロップは広告スタイル間で一貫していませんでした。
*トレーニング データと本番データの間での特徴の分布は一貫していません。
分析によると、ユーザーの位置と行動に関する 100 の数値特徴のうち、位置情報源に由来する 47 の特徴が生の特徴として使用されています。バイアスと分散の問題を解決するために推奨される実験は、10 個の直線的に修正されていない機能を設計することです。
ペナルティの検出とセンチメント
*初期データ検出では、群衆センチメント モデルに使用されるトレーニング データで、広範囲の密度のターゲット状態が示されます。
*すべてのペナルティ検出モデルは、確率的勾配降下法 (SGD) を使用した推論フェーズが過小に実行されていることを示しています。
*音声サンプルによると、キャッチフレーズの長さは地域によって 25% ~ 47% の間で異なります。
*グローバル ペナルティ検出モデルのパフォーマンスは、トレーニング セットと検証セットを比較すると、分散は低くなりますが、バイアスは高くなります。機能の変更を実装する前に、すべてのトレーニングと検証のケースを使用してバイアスと分散を確認する必要があります。
ポスト バッチ正規化統計 (PBN) は、推論元の論文で使用できるバッチ正規化の母平均と分散を評価する方法の Microsoft Cognitive Toolkit (CNTK) バージョンです。
CNTK では、カスタム ネットワークは BrainScriptNetworkBuilder を使用して定義され、CNTK ネットワーク記述言語「BrainScript」で記述されます。シナリオ:
ローカル ペナルティ検出モデルは、BrainScript を使用して作成する必要があります。
参考文献:
https://docs.microsoft.com/en-us/cognitive-toolkit/post-batch-normalization-statistics
トピック 1、ケース スタディ 1
概要
あなたは、プロのスポーツ イベントにデータ サイエンスを提供する会社のデータ サイエンティストです。モデルは、次のビジネス目標を達成するためのグローバルおよびローカル市場データになります。
*群衆の反応からの音声に基づいて、スポーツ イベントでのモバイル デバイス ユーザーの感情を理解します。
*広告に反応するユーザーの傾向にアクセスします。
*モバイル デバイスに配信される広告のスタイルをカスタマイズします。
*ビデオを使用して、ペナルティ イベントを検出します。
現在の環境
要件
* ペナルティ イベントの検出に使用されるメディアは、コンシューマ デバイスによって提供されます。メディアには、スポーツ イベント中に撮影され、ソーシャル メディアを使用して騙された画像や動画が含まれる場合があります。画像と動画のサイズと形式はさまざまです。
* モデル作成に使用できるデータは、7 年間のスポーツ イベント メディアで構成されています。スポーツ イベント メディアには、記録されたビデオ、ラジオ解説の書き起こし、関連するソーシャル メディア フィードからのログ、スポーツ イベント中にキャプチャされたフィードが含まれます。
*観衆の感情には、モノとステレオの両方の形式でイベント参加者から提出されたオーディオ録音が含まれます。
広告
* 広告応答モデルは、各イベントの開始時にトレーニングし、スポーツ イベント中に適用する必要があります。
* 市場セグメンテーション nxxlels は、同様の広告 resporr.r 履歴を最適化する必要があります。
* サンプリングは、同じ機能を共有するローカルおよびグローバル セグメンテーション モデルの相互および集合的排他性を保証する必要があります。
* ユーザーが広告に反応する傾向を判断する前に、ローカル市場セグメンテーション モデルが適用されます。
* データ サイエンティストは、モデルの劣化と崩壊を検出できなければなりません。
* 広告応答モデルは、非線形境界機能をサポートする必要があります。
* 広告傾向モデルではカットしきい値が 0.45 であり、加重カッパが 0.1 から逸脱すると再トレーニングが発生します
+/-5%。
* 広告傾向モデルは、次の図に示すコスト要因を使用します。
広告傾向モデルは、次の図に示す提案されたコスト ファクターを使用します。
現在および提案されているコスト要因シナリオのパフォーマンス曲線は、次の図に示されています。
ペナルティの検出とセンチメント
所見
*データ サイエンティストは、ペナルティ イベントの検出に複数の機械学習モデルを使用して、インテリジェントなソリューションを構築する必要があります。
*データ サイエンティストは、機械学習パイプラインで自動機能エンジニアリングとモデル構築を使用して、ローカル環境でノートブックを構築する必要があります。
*動的ワーカー割り当てを使用して Spark インスタンスを使用して再トレーニングするには、ノートブックをデプロイする必要があります
*ノートブックは、データのソースのみを再コード化するために、新しい Spark インスタンスで同じコードを使用して実行する必要があります。
*グローバル ペナルティ検出モデルは、トレーニング中に動的ランタイム グラフ計算を使用してトレーニングする必要があります。
*ローカル ペナルティ検出モデルは、BrainScript を使用して作成する必要があります。
* ローカル群衆センチメント モデルの実験では、ローカル ペナルティ検出データを組み合わせる必要があります。
* 群衆感情モデルは、歓声や既知のキャッチ フレーズなどの既知の音を識別しなければなりません。個々の群衆感情モデルは、同様の音を検出します。
* ローカル モデルの共有機能はすべて連続変数です。
* 共有機能は倍精度を使用する必要があります。後続のレイヤーには、総移動平均と標準偏差メトリックが使用可能である必要があります。
セグメント
本番環境の最初の数週間で、次のことが観察されました。
※広告の反応率が低下。
*ドロップは広告スタイル間で一貫していませんでした。
*トレーニング データと本番データの間での特徴の分布は一貫していません。
分析によると、ユーザーの位置と行動に関する 100 の数値特徴のうち、位置情報源に由来する 47 の特徴が生の特徴として使用されています。バイアスと分散の問題を解決するために推奨される実験は、10 個の直線的に修正されていない機能を設計することです。
ペナルティの検出とセンチメント
*初期データ検出では、群衆センチメント モデルに使用されるトレーニング データで、広範囲の密度のターゲット状態が示されます。
*すべてのペナルティ検出モデルは、確率的勾配降下法 (SGD) を使用した推論フェーズが過小に実行されていることを示しています。
*音声サンプルによると、キャッチフレーズの長さは地域によって 25% ~ 47% の間で異なります。
*グローバル ペナルティ検出モデルのパフォーマンスは、トレーニング セットと検証セットを比較すると、分散は低くなりますが、バイアスは高くなります。機能の変更を実装する前に、すべてのトレーニングと検証のケースを使用してバイアスと分散を確認する必要があります。

- 質問一覧「262問」
- 質問1 バイアスと分散の問題に対処するには、グローバル ペナルティ イ...
- 質問2 モデルのトレーニング時に選択されたハイパーパラメーターを最適
- 質問3 Windows 用の深層学習仮想マシンを構成します。 以下を実行する...
- 質問4 分類タスクを解決しています。 データセットが不均衡です。 分類...
- 質問5 Azure Machine Learning Studio を使用して二項分類モデルを作成...
- 質問6 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問7 モデルをトレーニングし、Azure Machine Learning ワークスペー...
- 質問8 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問9 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問10 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問11 スクリプト実行構成を使用して、実験としてスクリプトを実行する
- 質問12 Windows 用の深層学習仮想マシンを構成します。 以下を実行する...
- 質問13 近くの気象観測所からデータを収集します。次のデータを含む wea...
- 質問14 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問15 実験の実行が完了した後、Run オブジェクトの get_metrics メソ...
- 質問16 K-means アルゴリズムを使用してクラスタリングを実行しています...
- 質問17 音声認識の深層学習モデルを作成する予定です。 モデルは最新バ
- 質問18 決定木アルゴリズムを使用して分類モデルをトレーニングします。
- 質問19 Azure Storage アカウントの BLOB コンテナーを参照する trainin...
- 質問20 二項分類を実行する再帰型ニューラル ネットワークを構築してい
- 質問21 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問22 Azure Machine Learning をサポートするには、Azure Blob Storag...
- 質問23 分類タスクを解決しています。 データセットが不均衡です。 分類...
- 質問24 Azure Machine Learning Studio で実験を作成します。10.000 行...
- 質問25 Azure ML SDK を使用して実験を実行する準備をしていて、コンピ...
- 質問26 Azure Machine Learning Python SDK を使用して、複数のステップ...
- 質問27 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問28 ディープ ラーニング仮想マシン (DLVM) を使用して、Compute Uni...
- 質問29 CSV ファイルのセットには、販売記録が含まれています。すべての...
- 質問30 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問31 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問32 Azure Machine Learning Studio を使用して、機械学習実験を構築...
- 質問33 Azure Machine Learning サービスを使用するデータ サイエンス ...
- 質問34 ローカル ペナルティ検出データのスケーリング戦略を実装する必
- 質問35 新しい Azure サブスクリプションを作成します。サブスクリプシ...
- 質問36 株価を予測する機械学習モデルを実装しています。 モデルは Post...
- 質問37 Azure Machine Learning Studio を使用して二項分類モデルを作成...
- 質問38 Azure Machine Learning Studio で新しい実験を作成しています。...
- 質問39 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問40 イベント中のコール数を推定する回帰モデルを構築しています。
- 質問41 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問42 Azure Machine Learning Studio を使用して二項分類モデルを作成...
- 質問43 Azure Machine Learning Service を使用して、ニューラル ネット...
- 質問44 Azure Machine Learning を使用して、機械学習モデルをトレーニ...
- 質問45 次の形式の salesData という名前の Python データ フレームがあ...
- 質問46 トレーニング クラスターと推論クラスターを含む Azure Machine ...
- 質問47 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問48 モデルをトレーニングし、Azure Machine Learning ワークスペー...
- 質問49 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問50 モデルをトレーニングするときに、Azure Machine Learning のハ...
- 質問51 10,000 のデータ ポイントと 150 の特徴を持つ正規化された数値...
- 質問52 Azure Machine Learning Studio を使用して、マルチクラス分類を...
- 質問53 群集センチメント ローカル モデルの特徴量エンジニアリング戦略...
- 質問54 ディープ ラーニング仮想マシン (DLVM) を使用して、Compute Uni...
- 質問55 二項分類モデルを作成します。 モデルのパフォーマンスを評価す
- 質問56 Azure ML SDK を使用してバッチ推論パイプラインを作成します。...
- 質問57 機械学習モデルを作成しています。null 行を含むデータセットが...
- 質問58 Azure Machine Learning のリモート コンピューティングでトレー...
- 質問59 統計分布の非対称性を分析しています。 次の画像には、2 つのデ...
- 質問60 モデルの適合性の問題を修正する必要があります。 順番に実行す
- 質問61 Azure Machine Learning Studio を使用して、大規模なデータスト...
- 質問62 株価を予測する機械学習モデルを実装しています。 モデルは Post...
- 質問63 Azure Machine Learning Studio で実験を作成します。10.000 行...
- 質問64 実験の要件とデータセットに基づいて、Feature Based Feature Se...
- 質問65 次の数値機能を含む機能セットがあります: X、Y、および Z。 X、...
- 質問66 人が病気にかかっているかどうかを予測するために、バイナリ分類
- 質問67 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問68 半構造化、非構造化、および構造化されたデータ型を分析するため
- 質問69 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問70 Azure で Windows および Linux 用のデータ サイエンス仮想マシ...
- 質問71 あなたはワイナリーでデータサイエンティストとして雇われていま
- 質問72 Azure Machine Learning Studio の Two-Class Neural Network モ...
- 質問73 Azure Machine Learning Studio を使用してデータセットを分析し...
- 質問74 2,000 行を含むデータセットがあります。Azure Learning Studio ...
- 質問75 統計分布の非対称性を分析しています。 次の画像には、2 つのデ...
- 質問76 Azure Machine Learning Studio の Two-Class Neural Network モ...
- 質問77 Azure Machine Learning Studio で実験を作成します。10.000 行...
- 質問78 Azure Machine Learning を使用して、モデルをリアルタイム Web ...
- 質問79 次の形式の salesData という名前の Python データ フレームがあ...
- 質問80 Azure Machine Learning サービスで機械学習モデルをトレーニン...
- 質問81 広告応答のモデリング戦略を定義する必要があります。 順番に実
- 質問82 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問83 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問84 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問85 グローバル ペナルティ検出モデルのサンプリング戦略を構築する
- 質問86 Azure Machine Learning サービスを使用して、training.data と...
- 質問87 深層学習仮想マシン (DLVM) を使用して、Compute Unified Device...
- 質問88 ローカル ペナルティ検出データのスケーリング戦略を実装する必
- 質問89 モデルのトレーニング時に選択されたハイパーパラメーターを最適
- 質問90 都市の住宅販売データを含むデータセットがあります。データセッ
- 質問91 株価を予測する機械学習モデルを実装しています。 モデルは Post...
- 質問92 Azure Machine Learning を使用して機械学習モデルを作成します...
- 質問93 2,000 行を含むデータセットがあります。Azure Machine Learning...
- 質問94 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問95 音声認識の深層学習モデルを作成する予定です。 モデルは最新バ
- 質問96 x.1 x2 および x3 機能用の scikit-learn Python ライブラリを使...
- 質問97 あなたは分類タスクに取り組んでいます。生徒がサッカーをしたい
- 質問98 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問99 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問100 Azure Machine Learning サービスで機械学習モデルをトレーニン...
- 質問101 Azure Machine Learning Studio を使用して、2 つのデータ セッ...
- 質問102 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問103 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問104 Azure Machine Learning Service を使用して、ニューラル ネット...
- 質問105 次の形式の salesData という名前の Python データ フレームがあ...
- 質問106 イベント中の通話数を推定するための回帰モデルを構築しています
- 質問107 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問108 Azure Machine Learning デザイナーを使用して機械学習モデルを...
- 質問109 Azure Machine Learning を使用して、機械学習モデルをトレーニ...
- 質問110 完成したバイナリ分類機械学習モデルを評価しています。 精度を
- 質問111 グローバル ペナルティ検出モデルのサンプリング戦略を構築する
- 質問112 Azure Machine Learning Studio で時系列データセットを使用して...
- 質問113 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問114 クリーニングが必要な生のデータセットを分析しています。 Azure...
- 質問115 ビジネス アプリケーションで使用されるバッチ推論パイプライン
- 質問116 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問117 決定木アルゴリズムを使用しています。に等しいツリーの深さで適
- 質問118 クレジット カード詐欺の可能性のあるインスタンスを特定するた
- 質問119 モデルのトレーニング時に選択されたハイパーパラメーターを最適
- 質問120 広告応答のモデリング戦略を定義する必要があります。 順番に実
- 質問121 バイアスと分散の問題に対処するには、グローバル ペナルティ イ...
- 質問122 組織は、一連のラベル付き写真を使用するマルチクラスの画像分類
- 質問123 次の形式の salesData という名前の Python データ フレームがあ...
- 質問124 モデルのトレーニング要件に適した早期停止基準を実装する必要が
- 質問125 Azure Machine Learning ワークスペースを作成し、開発環境をセ...
- 質問126 Azure Machine Learning Studio で多重線形回帰モデルを作成して...
- 質問127 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問128 CSV ファイルからテキストを前処理する予定です。Azure Machine ...
- 質問129 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問130 Age 列に異常値が存在するかどうかを視覚的に識別し、異常値を削...
- 質問131 (Exhibit) 次の各ステートメントについて、該当する場合は [はい...
- 質問132 Azure Machine Learning サービスを使用するデータ サイエンス ...
- 質問133 大規模なデータセットを Azure Machine Learning Studio から We...
- 質問134 K-means アルゴリズムを使用してクラスタリングを実行しています...
- 質問135 機械学習モデルを作成しています。null 行を含むデータセットが...
- 質問136 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問137 Azure Machine Learning デザイナーを使用してトレーニング パイ...
- 質問138 モデル フレーミング要件に対して、順列機能の重要性モジュール
- 質問139 次のコードを使用して、Azure Machine Learning で実験としてス...
- 質問140 Azure Machine Learning ワークスペースには、 という名前のデー...
- 質問141 ディープ ラーニング仮想マシン (DLVM) を使用して、Compute Uni...
- 質問142 150 を超えるフィーチャを含むデータセットがあります。データセ...
- 質問143 モデルのトレーニング要件のために、Permutation Feature Import...
- 質問144 モデルをトレーニングするときに、Azure Machine Learning のハ...
- 質問145 決定木アルゴリズムを使用しています。ツリーの深さ 10 で十分に...
- 質問146 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問147 実験の要件とデータセットに基づいて、Feature Based Feature Se...
- 質問148 近くの気象観測所からデータを収集します。次のデータを含む wea...
- 質問149 マルチクラスの画像分類ディープ ラーニング モデルを作成します...
- 質問150 大規模なデータセットを Azure Machine Learning Studio から We...
- 質問151 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問152 Azure Machine Learning Studio を使用して二項分類モデルを作成...
- 質問153 クリーニングが必要な生のデータセットを分析しています。 Azure...
- 質問154 モデルの適合性の問題を修正する必要があります。 順番に実行す
- 質問155 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問156 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問157 あなたはワイナリーでデータサイエンティストとして雇われていま
- 質問158 実験の実行が完了した後、Run オブジェクトの get_metrics メソ...
- 質問159 機械学習モデルを使用してインテリジェントなソリューションを構
- 質問160 Azure Databricks ワークスペースと、リンクされた Azure Machin...
- 質問161 Azure Machine Learning Studio を使用して、大規模なデータスト...
- 質問162 猫と犬を識別するためにディープ ラーニング モデルを交配させま...
- 質問163 Azure Machine Learning Studio を使用して、機械学習実験を構築...
- 質問164 Age 列に異常値が存在するかどうかを視覚的に識別し、異常値を削...
- 質問165 10,000 のデータ ポイントと 150 の特徴を持つ正規化された数値...
- 質問166 あなたはワイナリーでデータサイエンティストとして雇われていま
- 質問167 モデルを Azure Container Instance にデプロイします。 モデル ...
- 質問168 短い文章形式で書かれた 12,000 件のカスタマー レビューを含む ...
- 質問169 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問170 Azure Machine Learning ワークスペースにいくつかの機械学習モ...
- 質問171 Azure Machine Learning を使用して、モデルをリアルタイム Web ...
- 質問172 Windows 用の深層学習仮想マシンを構成します。 以下を実行する...
- 質問173 実験の要件とデータセットに基づいて、Feature Based Feature Se...
- 質問174 Azure Machine Learning SDK を使用して、分類モデルをトレーニ...
- 質問175 Azure Machine Learning Studio で実験を作成します。10,000 行...
- 質問176 Azure Storage アカウントの BLOB コンテナーを参照する trainin...
- 質問177 次のバージョンのモデルを登録します。 (Exhibit) Azure ML Pyth...
- 質問178 マルチクラスの画像分類ディープ ラーニング モデルを作成します...
- 質問179 ノートブックで Azure Machine Learning SDK を使用して、実験フ...
- 質問180 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問181 短い文章形式で書かれた 12,000 件のカスタマー レビューを含む ...
- 質問182 Azure で Windows および Linux 用のデータ サイエンス仮想マシ...
- 質問183 地元のタクシー会社からの履歴データを含むデータセットを分析し
- 質問184 Azure Machine Learning デザイナーを使用して実験を構築してい...
- 質問185 クレジット カード詐欺の可能性のあるインスタンスを特定するた
- 質問186 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問187 Python で機械学習モデルを作成しています。提供されたデータセ...
- 質問188 あなたは分類タスクに取り組んでいます。生徒がサッカーをしたい
- 質問189 Azure Machine Learning サービスで機械学習モデルをトレーニン...
- 質問190 10,000 のデータ ポイントと 150 の特徴を持つ正規化された数値...
- 質問191 あなたは実践的なワークショップを数人の学生に提供する予定です
- 質問192 x.1 x2 および x3 機能用の scikit-learn Python ライブラリを使...
- 質問193 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問194 Azure Machine Learning Studio で多重線形回帰モデルを作成して...
- 質問195 Age 列に異常値が存在するかどうかを視覚的に識別し、異常値を削...
- 質問196 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問197 x.1 x2 および x3 機能用の scikit-learn Python ライブラリを使...
- 質問198 あなたは参加者に Docker for Windows を紹介するための実践的な...
- 質問199 ノートブックで Azure Machine Learning SDK を使用して、実験フ...
- 質問200 あなたは分類タスクに取り組んでいます。生徒がサッカーをしたい
- 質問201 クリーニングが必要な生のデータセットを分析しています。 Azure...
- 質問202 英語のテキスト コンテンツをフランス語のテキスト コンテンツに...
- 質問203 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問204 あなたは Azure Machine Learning ワークスペースの所有者です。...
- 質問205 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問206 分類タスクを解決しています。 データセットが不均衡です。 分類...
- 質問207 バッチ推論パイプラインで使用する予定のモデルを登録します。
- 質問208 地元のタクシー会社からの履歴データを含むデータセットを分析し
- 質問209 データセットの構造が一致するように、メタデータの編集モジュー
- 質問210 Azure Machine Learning ワークスペースでモデルをトレーニング...
- 質問211 一連のラベル付き画像を使用するマルチクラス画像分類深層学習モ
- 質問212 モデルのトレーニング要件のために、Permutation Feature Import...
- 質問213 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問214 ユーザーが広告に反応する傾向を判断するには、モデル開発戦略を
- 質問215 次のコードがあります。このコードは、スクリプトを実行するため
- 質問216 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問217 PyTorch フレームワークを使用して、マルチクラスの画像分類ディ...
- 質問218 提供されたトレーニング セットを使用して、バイナリ分類モデル
- 質問219 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問220 Azure を使用して機械学習、実験を開発しています。次の画像は、...
- 質問221 Azure Machine Learning Studio を使用して、大規模なデータスト...
- 質問222 短い文章形式で書かれた 12,000 件のカスタマー レビューを含む ...
- 質問223 Azure Machine Learning を使用して、モデルのトレーニングと登...
- 質問224 Azure Storage BLOB コンテナー用に ml-data という名前のデータ...
- 質問225 データセットに対して特徴量エンジニアリングを実行しています。
- 質問226 Azure Machine Learning Studio で新しい実験を作成しています。...
- 質問227 チーム データ サイエンス環境の構築を計画しています。機械学習...
- 質問228 C サポート ベクター分類を使用して、不均衡なトレーニング デー...
- 質問229 Azure Machine Learning サービスを使用するデータ サイエンス ...
- 質問230 Azure Machine Learning デザイナーを使用して、リアルタイム サ...
- 質問231 短い文章形式で書かれた 12,000 件のカスタマー レビューを含む ...
- 質問232 モデルのトレーニング要件に従って、Permutation Feature Import...
- 質問233 Azure Machine Learning を使用して機械学習モデルを作成します...
- 質問234 マルチクラスの画像分類ディープ ラーニング モデルを作成します...
- 質問235 あなたは Azure Machine Learning Service を使用して、ニューラ...
- 質問236 次のように定義された 6 つのデータ ポイントを含む Python NumP...
- 質問237 バイアスと分散の問題に対処するには、グローバル ペナルティ イ...
- 質問238 モデルのトレーニング要件に従って、Permutation Feature Import...
- 質問239 データセットの構造が一致するように、メタデータの編集モジュー
- 質問240 モデルをトレーニングし、Azure Machine Learning ワークスペー...
- 質問241 モデル フレーミング要件に対して、順列機能の重要性モジュール
- 質問242 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問243 機械学習モデルを使用してインテリジェントなソリューションを構
- 質問244 Python で機械学習モデルを作成しています。提供されたデータセ...
- 質問245 人が病気にかかっているかどうかを予測するために、バイナリ分類
- 質問246 半構造化、非構造化、および構造化されたデータ型を分析するため
- 質問247 モデルのトレーニング要件に適した早期停止基準を実装する必要が
- 質問248 CSV ファイルからテキストを前処理する予定です。Azure Machine ...
- 質問249 ローカル モデルの特徴抽出戦略を構築する必要があります。 コー...
- 質問250 Python で機械学習モデルを作成しています。提供されたデータセ...
- 質問251 Azure Machine Learning Studio で分類タスクを実行しています。...
- 質問252 C サポート ベクター分類を使用して、不均衡なトレーニング デー...
- 質問253 イベント中の通話数を推定するための回帰モデルを構築しています
- 質問254 モデルのトレーニング要件に従って、Permutation Feature Import...
- 質問255 Azure Machine Learning を使用して、モデルをリアルタイム Web ...
- 質問256 機械学習モデルを使用してインテリジェントなソリューションを構
- 質問257 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問258 機械学習モデルを作成しています。null 行を含むデータセットが...
- 質問259 CPU ベースのコンピューティング クラスターと Azure Kubernetes...
- 質問260 データセットに対して特徴量エンジニアリングを実行しています。
- 質問261 次の数値機能を含む機能セットがあります: X、Y、および Z。 X、...
- 質問262 2,000 行を含むデータセットがあります。Azure Learning Studio ...
