- ホーム
- Microsoft
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- Microsoft.DP-100.v2022-07-18.q157
- 質問120
有効的なDP-100問題集はJPNTest.com提供され、DP-100試験に合格することに役に立ちます!JPNTest.comは今最新DP-100試験問題集を提供します。JPNTest.com DP-100試験問題集はもう更新されました。ここでDP-100問題集のテストエンジンを手に入れます。
DP-100問題集最新版のアクセス
「528問、30% ディスカウント、特別な割引コード:JPNshiken」
X、Y、およびZの数値機能を含む機能セットがあります。
X、Y、およびZフィーチャのポアソン相関係数(r値)を次の画像に示します。

ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

X、Y、およびZフィーチャのポアソン相関係数(r値)を次の画像に示します。
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。
正解:

Explanation:
ボックス1:0.859122
ボックス2:正の線形関係
+1は、強い正の線形関係を示します
-1は強い負の線形相関を示します
0は、2つの変数間に線形関係がないことを示します。
参照:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation
トピック1、ケーススタディ
概要
あなたは、プロのスポーツイベントにデータサイエンスを提供する会社のデータサイエンティストです。モデルは、次のビジネス目標を達成するためのグローバルおよびローカルの市場データになります。
*群衆の反応からの音声に基づいて、スポーツイベントでのモバイルデバイスユーザーの感情を理解します。
*広告に反応するユーザーの傾向にアクセスします。
*モバイルデバイスに配信される広告のスタイルをカスタマイズします。
*ペナルティイベントを検出するためにビデオを使用してください。
現在の環境
要件
*ペナルティイベントの検出に使用されるメディアは、消費者向けデバイスによって提供されます。メディアには、スポーツイベント中にキャプチャされ、ソーシャルメディアを使用してスネアされた画像やビデオが含まれる場合があります。画像と動画のサイズと形式はさまざまです。
*モデル構築に利用できるデータは、7年間のスポーツイベントメディアで構成されています。スポーツイベントのメディアには、録画されたビデオ、ラジオ解説のトランスクリプト、およびスポーツイベント中にキャプチャされた関連するソーシャルメディアフィードフィードからのログが含まれます。
*群衆の感情には、モノラル形式とステレオ形式の両方でイベント参加者から提出されたオーディオ録音が含まれます。
広告
*広告応答モデルは、各イベントの開始時にトレーニングし、スポーツイベント中に適用する必要があります。
*マーケットセグメンテーションnxxlelsは、同様の広告resporr.r履歴に合わせて最適化する必要があります。
*サンプリングは、同じ機能を共有する相互および集合的な排他性のローカルおよびグローバルセグメンテーションモデルを保証する必要があります。
*広告に応答するユーザーの傾向を判断する前に、ローカルマーケットセグメンテーションモデルが適用されます。
*データサイエンティストは、モデルの劣化と減衰を検出できる必要があります。
*広告応答モデルは、非線形境界機能をサポートする必要があります。
*広告傾向モデルはカットしきい値が0.45であり、加重カッパが0.1 +/- 5%から外れると再トレーニングが発生します。
*広告傾向モデルは、次の図に示すコスト係数を使用します。
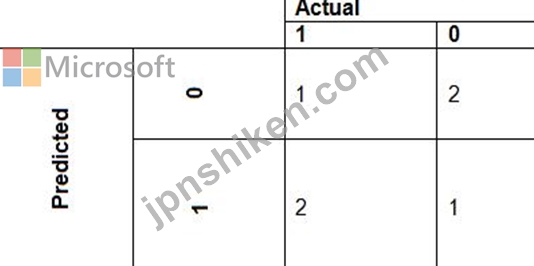
広告傾向モデルは、次の図に示す提案されたコスト要因を使用します。
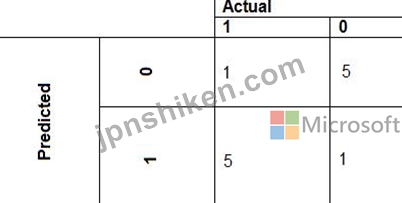
現在および提案されているコスト要因シナリオのパフォーマンス曲線を次の図に示します。

ペナルティの検出と感情
調査結果
*データサイエンティストは、ペナルティイベントの検出に複数の機械学習モデルを使用してインテリジェントなソリューションを構築する必要があります。
*データサイエンティストは、機械学習パイプラインでの自動特徴エンジニアリングとモデル構築を使用して、ローカル環境でノートブックを構築する必要があります。
*動的なワーカー割り当てでSparkインスタンスを使用して再トレーニングするには、ノートブックをデプロイする必要があります
*ノートブックは、データのソースのみを再コード化するために、新しいSparkインスタンスで同じコードで実行する必要があります。
*グローバルペナルティ検出モデルは、トレーニング中に動的ランタイムグラフ計算を使用してトレーニングする必要があります。
*ローカルペナルティ検出モデルは、BrainScriptを使用して作成する必要があります。
*地域の群衆感情モデルの実験では、地域のペナルティ検出データを組み合わせる必要があります。
*群衆の感情モデルは、歓声や既知のキャッチフレーズなどの既知の音を識別する必要があります。個々の群衆感情モデルは、同様の音を検出します。
*ローカルモデルのすべての共有機能は連続変数です。
*共有機能は倍精度を使用する必要があります。後続のレイヤーには、実行中の平均と標準偏差の合計メトリックが使用可能である必要があります。
セグメント
生産の最初の数週間で、次のことが観察されました。
*広告の回答率は低下しました。
*ドロップは広告スタイル間で一貫していませんでした。
*トレーニングデータと本番データ全体での機能の分散には一貫性がありません。
分析によると、ユーザーの位置と行動に関する100の数値特徴のうち、位置ソースからの47の特徴が生の特徴として使用されています。偏りと分散の問題を解決するために推奨される実験は、10個の線形に修正されていない特徴を設計することです。
ペナルティの検出と感情
*最初のデータ検出では、群集感情モデルに使用されるトレーニングデータに、ターゲット状態の密度が広範囲にわたって示されています。
*すべてのペナルティ検出モデルは、確率的勾配降下法(SGD)を使用した推論フェーズがあまりにも多く実行されていることを示しています。
*オーディオサンプルでは、キャッチフレーズの長さが地域によって25%〜47%の間で変化することが示されています。
*グローバルペナルティ検出モデルのパフォーマンスは、トレーニングセットと検証セットを比較すると、分散は低くなりますが、バイアスが高くなります。機能の変更を実装する前に、すべてのトレーニングと検証のケースを使用してバイアスと分散を確認する必要があります。

- 質問一覧「157問」
- 質問1 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問2 AzureMachineLearningワークスペースから実行される実験を取得す...
- 質問3 Azure Machine Learningサービスを使用して、training.dataとい...
- 質問4 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問5 AzureのWindowsおよびLinux用のデータサイエンス仮想マシン(DSV...
- 質問6 AzureMachineLearningワークスペースを作成します。 次の要件を...
- 質問7 AzureMachineLearningのHyperdrive機能を使用してモデルをトレー...
- 質問8 モデルトレーニング要件に適した早期停止基準を実装する必要があ
- 質問9 モデルのトレーニング要件に従って、順列特徴重要度モジュールを
- 質問10 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問11 Azure Machine Learning Studioを使用して、機械学習実験を構築...
- 質問12 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問13 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問14 あなたは分類タスクに取り組んでいます。学生がサッカーをしたい
- 質問15 データセットの構造が一致するように、メタデータの編集モジュー
- 質問16 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問17 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問18 二項分類を実行するためにリカレントニューラルネットワークを構
- 質問19 機械学習モデルを作成しています。 データ内の外れ値を特定する
- 質問20 次の形式のsalesDataという名前のPythonデータフレームがありま...
- 質問21 CSVファイルからテキストを前処理することを計画しています。Azu...
- 質問22 Azure ML SDKを使用して実験を実行する準備をしており、コンピュ...
- 質問23 Azure Machine Learning Serviceを使用して、ニューラルネットワ...
- 質問24 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問25 Azure Machine Learningを使用して、dataset1という名前のデータ...
- 質問26 150を超える機能を含むデータセットがあります。データセットを...
- 質問27 イベント中の呼び出し数を推定する回帰モデルを構築しています。
- 質問28 クレジットカード詐欺の可能性のある事例を特定するために、銀行
- 質問29 DockerforWindowsを参加者に紹介するための実践的なワークショッ...
- 質問30 Azure Machine Learning Designerを使用して、回帰モデルのトレ...
- 質問31 あなたは線形回帰モデルを作成するデータサイエンティストです。
- 質問32 AzureMachineLearningワークスペースでモデルをトレーニングして...
- 質問33 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問34 Azure Machine Learningを使用して、モデルをリアルタイムWebサ...
- 質問35 Azure ML SDKを使用して、バッチ推論パイプラインを作成します。...
- 質問36 ラベル付けされた写真のセットを使用するマルチクラスの画像分類
- 質問37 分類タスクを解決しています。 k分割交差検定を使用して、限られ...
- 質問38 K-meansアルゴリズムを使用してクラスタリングを実行しています...
- 質問39 Azure Machine Learningを使用して、機械学習モデルをトレーニン...
- 質問40 Azure Machine Learning Studioを使用して、2つのデータセットが...
- 質問41 既存のモデルを再トレーニングします。 モデルの現在のバージョ
- 質問42 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問43 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問44 x.1x2およびx3機能用のscikit-learnPythonライブラリを使用して...
- 質問45 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問46 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問47 一連のデータサイエンス実験用に、事前に構築された開発環境を選
- 質問48 ホテル予約Webサイトの不正取引を予測するための機械学習モデル...
- 質問49 Azure Machine Learning Studioを使用して、大規模なデータスト...
- 質問50 モデルのトレーニングに使用されるPythonコードを含むJupyterNot...
- 質問51 群集感情のローカルモデルの特徴エンジニアリング戦略を実装する
- 質問52 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問53 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問54 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問55 音声認識ディープラーニングモデルを作成する予定です。 モデル
- 質問56 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問57 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問58 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問59 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問60 [年齢]列に外れ値が存在するかどうかを視覚的に識別し、外れ値を...
- 質問61 CSVファイルからテキストを前処理することを計画しています。Azu...
- 質問62 同僚は、次のコードを使用して、機械学習サービスワークスペース
- 質問63 都市の住宅販売データを含むデータセットがあります。データセッ
- 質問64 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問65 バイアスと分散の問題に対処するには、グローバルペナルティイベ
- 質問66 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問67 Azure MachineLearningStudioで重回帰モデルを作成しています。 ...
- 質問68 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問69 数人の学生に実践的なワークショップを提供する予定です。このワ
- 質問70 C-サポートベクター分類を使用して、不均衡なトレーニングデータ...
- 質問71 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問72 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問73 AzureMachineLearningのHyperdrive機能を使用してモデルをトレー...
- 質問74 短い文の形式で書かれた12,000件の顧客レビューを含むCSVファイ...
- 質問75 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問76 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問77 Azure MachineLearningStudioで実験を作成します-10.000行を含む...
- 質問78 組織は、ラベル付けされた写真のセットを使用するマルチクラスの
- 質問79 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問80 トレーニングエラー値と検証エラー値の間に大きな違いがあるモデ
- 質問81 x.1x2およびx3機能用のscikit-learnPythonライブラリを使用して...
- 質問82 データセットに対してフィルターベースの特徴選択を実行していま
- 質問83 広告レスポンスのモデリング戦略を定義する必要があります。 順
- 質問84 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問85 さまざまな都市の持ち家の人口統計データを調査する予定です。デ
- 質問86 ラベル付けされた写真のセットを使用するマルチクラスの画像分類
- 質問87 ラベル付けされた画像のセットを使用するマルチクラスの画像分類
- 質問88 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問89 二項分類を実行するためにリカレントニューラルネットワークを構
- 質問90 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問91 提供されているトレーニングセットを使用して、二項分類モデルを
- 質問92 あなたは、画像分類のための深い畳み込みニューラルネットワーク
- 質問93 AzureMachineLearningでリモートコンピューティングのトレーニン...
- 質問94 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問95 データの視覚化要件に従って、診断テスト評価用の視覚化を作成す
- 質問96 財務チームは、finance-dataという名前のAzureStorageBLOBコンテ...
- 質問97 フォルダを参照するcsvjolderという名前のファイルデータセット...
- 質問98 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問99 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問100 データの視覚化要件に従って、診断テスト評価用の視覚化を作成す
- 質問101 Azure Machine Learning Studioの2クラスニューラルネットワーク...
- 質問102 機械学習モデルをトレーニングします。 テスト用のリアルタイム
- 質問103 音声認識ディープラーニングモデルを作成する予定です。 モデル
- 質問104 自動機械学習を使用して回帰モデルをトレーニングすることを計画
- 質問105 ペナルティイベント検出のプロセスを定義する必要があります。
- 質問106 AccessibilityToHighway列の欠落データを置き換える必要がありま...
- 質問107 あなたのチームは、データエンジニアリングとデータサイエンスの
- 質問108 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問109 Azure MachineLearningStudioに時系列データセットがあります。 ...
- 質問110 デシジョンツリーアルゴリズムを使用しています。に等しい木の深
- 質問111 モデルトレーニング要件に合わせて、順列特徴重要度モジュールを
- 質問112 あなたは分類タスクに取り組んでいます。学生がサッカーをしたい
- 質問113 AzureMachineLearningデザイナーを使用してトレーニングパイプラ...
- 質問114 Azureを使用して機械学習、実験を開発しています。 次の画像は、...
- 質問115 AzureのWindowsおよびLinux用のデータサイエンス仮想マシン(DSV...
- 質問116 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問117 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問118 バイアスと分散の問題に対処するには、グローバルペナルティイベ
- 質問119 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問120 X、Y、およびZの数値機能を含む機能セットがあります。 X、Y、お...
- 質問121 分類モデルをトレーニングするデータを含むコンマ区切り値(CSV...
- 質問122 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問123 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問124 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問125 あなたはワイナリーでデータサイエンティストとして雇われていま
- 質問126 人が病気にかかっているかどうかを予測するために、二項分類モデ
- 質問127 デシジョンツリーアルゴリズムを使用しています。に等しい木の深
- 質問128 CPUベースのコンピューティングクラスターとAzureKubernetesServ...
- 質問129 モデルをトレーニングするためのAzureMachineLearningコンピュー...
- 質問130 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問131 Azure Machine Learning Serviceを使用して、ニューラルネットワ...
- 質問132 Azure MachineLearningStudioで実験を作成します-10.000行を含む...
- 質問133 あなたは銀行で働いているデータサイエンティストであり、Azure ...
- 質問134 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問135 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問136 あなたはホテル予約ウェブサイト会社で働いているデータサイエン
- 質問137 STANDARD_D1仮想マシンイメージを使用して、ComputeOneという名...
- 質問138 Python言語を使用して、グローバルペナルティ検出モデルのサンプ...
- 質問139 トレーニングクラスターと推論クラスターを含むAzureMachineLear...
- 質問140 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問141 トレーニング済みのモデルをAzureMachineLearningワークスペース...
- 質問142 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問143 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問144 AzureMachineLearningで機械学習モデルをトレーニングしています...
- 質問145 数人の学生に実践的なワークショップを提供する予定です。このワ
- 質問146 Azure MachineLearningStudioを使用してバイナリ分類モデルを作...
- 質問147 あなたは、猫と犬を識別するために深層学習モデルを交配します。
- 質問148 次のバージョンのモデルを登録します。 (Exhibit) Azure ML Pyth...
- 質問149 英語のテキストコンテンツをフランス語のテキストコンテンツに翻
- 質問150 AzureMachineLearningサービスで機械学習モデルをトレーニングす...
- 質問151 AzureMachineLearningワークスペースを使用します。 Webサービス...
- 質問152 マルチクラスの画像分類深層学習モデルを作成します。 モデルは
- 質問153 Azure MachineLearningStudioで分類タスクを実行しています。 提...
- 質問154 AzureMachineLearningワークスペースで自動機械学習実験を実行し...
- 質問155 ペナルティイベント検出のプロセスを定義する必要があります。
- 質問156 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問157 AccessibilityToHighway列の欠落データを置き換える必要がありま...
