- ホーム
- Microsoft
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- Microsoft.DP-100.v2022-07-18.q157
- 質問51
有効的なDP-100問題集はJPNTest.com提供され、DP-100試験に合格することに役に立ちます!JPNTest.comは今最新DP-100試験問題集を提供します。JPNTest.com DP-100試験問題集はもう更新されました。ここでDP-100問題集のテストエンジンを手に入れます。
DP-100問題集最新版のアクセス
「528問、30% ディスカウント、特別な割引コード:JPNshiken」
群集感情のローカルモデルの特徴エンジニアリング戦略を実装する必要があります。
あなたは何をするべきか?
あなたは何をするべきか?
正解:D
線形判別分析法は、連続変数でのみ機能し、カテゴリ変数または順序変数では機能しません。
線形判別分析は、変数の平均を比較することによって機能するという点で、分散分析(ANOVA)に似ています。
シナリオ:
データサイエンティストは、機械学習パイプラインでの自動特徴エンジニアリングとモデル構築を使用して、ローカル環境でノートブックを構築する必要があります。
地域の群衆感情モデルの実験では、地域のペナルティ検出データを組み合わせる必要があります。
ローカルモデルのすべての共有機能は連続変数です。
不正解:
B:ピアソンのRテストと呼ばれることもあるピアソン相関係数は、2つの変数間の線形関係を測定する統計値です。係数値を調べることにより、2つの変数間の関係の強さ、およびそれらが正の相関関係にあるか負の相関関係にあるかについて何かを推測できます。
C:スピアマンの相関係数は、ノンパラメトリックおよび非正規分布のデータで使用するように設計されています。スピアマンの係数は、2つの変数間の統計的依存性のノンパラメトリック尺度であり、ギリシャ文字のrhoで表されることもあります。スピアマンの係数は、2つの変数が単調に関連している度合いを表します。順序変数で使用できるため、スピアマンの順位相関とも呼ばれます。
参照:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/fisher-linear-discriminant-analysis
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation機能エンジニアリングテストレット2の実行ケーススタディこれはケーススタディです。ケーススタディは個別にタイミングが調整されていません。各ケースを完了するのに必要なだけの試験時間を使用できます。ただし、この試験には追加のケーススタディとセクションがある場合があります。あなたはあなたが提供された時間内にこの試験に含まれるすべての質問を完了することができることを確実にするためにあなたの時間を管理しなければなりません。
ケーススタディに含まれている質問に答えるには、ケーススタディで提供されている情報を参照する必要があります。ケーススタディには、ケーススタディで説明されているシナリオに関する詳細情報を提供する展示やその他のリソースが含まれている場合があります。このケーススタディでは、各質問は他の質問から独立しています。
このケーススタディの最後に、レビュー画面が表示されます。この画面では、試験の次のセクションに進む前に、回答を確認して変更を加えることができます。新しいセクションを開始した後は、このセクションに戻ることはできません。
ケーススタディを開始するには
このケーススタディの最初の質問を表示するには、[次へ]ボタンをクリックします。質問に答える前に、左側のペインのボタンを使用して、ケーススタディの内容を調べてください。これらのボタンをクリックすると、ビジネス要件、既存の環境、問題の説明などの情報が表示されます。ケーススタディに[すべての情報]タブがある場合、表示される情報は後続のタブに表示される情報と同じであることに注意してください。質問に答える準備ができたら、[質問]ボタンをクリックして質問に戻ります。
概要
あなたは、米国の質の高い私有および商業用不動産を専門とする会社であるFabrikamResidencesのデータサイエンティストです。Fabrikam Residencesはヨーロッパへの進出を検討しており、ヨーロッパの主要都市の個人住宅の価格を調査するように依頼しました。
Azure Machine Learning Studioを使用して、プロパティの中央値を測定します。線形回帰モジュールとベイズ線形回帰モジュールを使用して、不動産価格を予測する回帰モデルを作成します。
データセット
ロンドンとパリの2つの都市のプロパティの詳細を含む、CSV形式の2つのデータセットがあります。両方のファイルを別々のデータセットとしてAzureMachineLearning Studioに追加し、実験の開始点にします。両方のデータセットには、次の列が含まれています。
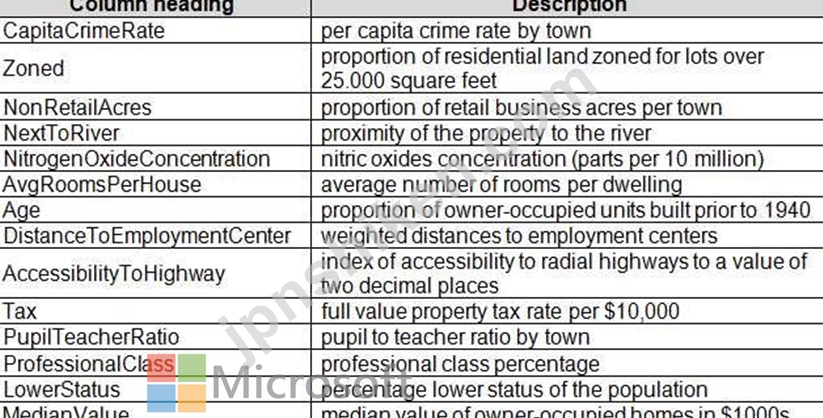
最初の調査では、データセットの構造はMedianValue列を除いて同一であることが示されています。
小さいパリのデータセットにはテキスト形式のMedianValueが含まれていますが、大きいロンドンのデータセットには数値形式のMedianValueが含まれています。
データの問題
欠落している値
両方のデータセットのAccessibilityToHighway列に欠落している値が含まれています。欠落しているデータは、欠落している値を入力する前に、データ内の他の変数を使用して条件付きでモデル化されるように、新しいデータに置き換える必要があります。
各データセットの列には、欠落している値とnull値が含まれています。データセットには、多くの外れ値も含まれています。Age列には、外れ値の割合が高くなっています。Age列に外れ値がある行を削除する必要があります。
MedianValue列とAvgRoomsInHouse列は、どちらも数値形式のデータを保持します。2つの列の関係をより詳細に分析するには、特徴選択アルゴリズムを選択する必要があります。
モデルフィット
モデルは過剰適合の兆候を示しています。過剰適合を減らす、より洗練された回帰モデルを作成する必要があります。
実験要件
パフォーマンスを評価するには、線形回帰モジュールとベイズ線形回帰モジュールを相互検証するように実験を設定する必要があります。いずれの場合も、データセットの予測子はMedianValueという名前の列です。ParisデータセットのMedianValue列のデータ型が、Londonデータセットの構造と一致していることを確認する必要があります。
結果を予測するには、データの列に優先順位を付ける必要があります。関係を測定するには、ノンパラメトリック統計を使用する必要があります。
MediaValue列とAvgRoomsinHouse列の間の関係を分析するには、特徴選択アルゴリズムが必要です。
モデルトレーニング
順列特徴の重要性
訓練されたモデルとテストデータセットが与えられた場合、特徴変数の順列特徴重要度スコアを計算する必要があります。モデルの絶対適合を決定する必要があります。
ハイパーパラメータ
学習フェーズを高速化するには、モデル学習プロセスでハイパーパラメータを構成する必要があります。さらに、この構成では、各評価間隔で最もパフォーマンスの低い実行をキャンセルする必要があります。これにより、成功する可能性が高いモデルに労力とリソースが振り向けられます。
モデルがハイパーパラメータ調整で計算リソースを効率的に使用しない可能性があることを懸念しています。また、モデルによって全体的なチューニング時間の増加が妨げられる可能性があることも懸念されます。したがって、有望な仕事を終わらせることなく節約を提供するモデルに早期打ち切り基準を実装する必要があります。
テスト
Azure MachineLearningStudioのPartitionandSampleモジュールを使用したサンプリングに基づいて、データセットの複数のパーティションを作成する必要があります。
相互検証
相互検証のために、3つの等しいパーティションを作成する必要があります。また、テストデータセットとトレーニングデータセットの行が各都市の主要な川の近くにあるプロパティによって均等に分割されるように、交差検定プロセスを構成する必要があります。データがサンプリングプロセスを通過する前に、このタスクを完了する必要があります。
線形回帰モジュール
線形回帰モジュールをトレーニングするときは、モデルで使用するのに最適な機能を決定する必要があります。機能重要度プロセスが完了する前後のパフォーマンスを測定するために提供される標準メトリックを選択できます。複数のトレーニングモデル間での機能の分散は一貫している必要があります。
データの視覚化
テスト結果をFabrikamResidencesチームに提供する必要があります。結果の提示を支援するためにデータの視覚化を作成します。
モデルの診断テスト評価を実行するには、受信者動作特性(ROC)曲線を作成する必要があります。2クラスのDecisionForestモジュールと2クラスのDecisionJungleモジュールを相互に比較するには、AzureLearningStudioでROC曲線を作成するための適切な方法を選択する必要があります。
線形判別分析は、変数の平均を比較することによって機能するという点で、分散分析(ANOVA)に似ています。
シナリオ:
データサイエンティストは、機械学習パイプラインでの自動特徴エンジニアリングとモデル構築を使用して、ローカル環境でノートブックを構築する必要があります。
地域の群衆感情モデルの実験では、地域のペナルティ検出データを組み合わせる必要があります。
ローカルモデルのすべての共有機能は連続変数です。
不正解:
B:ピアソンのRテストと呼ばれることもあるピアソン相関係数は、2つの変数間の線形関係を測定する統計値です。係数値を調べることにより、2つの変数間の関係の強さ、およびそれらが正の相関関係にあるか負の相関関係にあるかについて何かを推測できます。
C:スピアマンの相関係数は、ノンパラメトリックおよび非正規分布のデータで使用するように設計されています。スピアマンの係数は、2つの変数間の統計的依存性のノンパラメトリック尺度であり、ギリシャ文字のrhoで表されることもあります。スピアマンの係数は、2つの変数が単調に関連している度合いを表します。順序変数で使用できるため、スピアマンの順位相関とも呼ばれます。
参照:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/fisher-linear-discriminant-analysis
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation機能エンジニアリングテストレット2の実行ケーススタディこれはケーススタディです。ケーススタディは個別にタイミングが調整されていません。各ケースを完了するのに必要なだけの試験時間を使用できます。ただし、この試験には追加のケーススタディとセクションがある場合があります。あなたはあなたが提供された時間内にこの試験に含まれるすべての質問を完了することができることを確実にするためにあなたの時間を管理しなければなりません。
ケーススタディに含まれている質問に答えるには、ケーススタディで提供されている情報を参照する必要があります。ケーススタディには、ケーススタディで説明されているシナリオに関する詳細情報を提供する展示やその他のリソースが含まれている場合があります。このケーススタディでは、各質問は他の質問から独立しています。
このケーススタディの最後に、レビュー画面が表示されます。この画面では、試験の次のセクションに進む前に、回答を確認して変更を加えることができます。新しいセクションを開始した後は、このセクションに戻ることはできません。
ケーススタディを開始するには
このケーススタディの最初の質問を表示するには、[次へ]ボタンをクリックします。質問に答える前に、左側のペインのボタンを使用して、ケーススタディの内容を調べてください。これらのボタンをクリックすると、ビジネス要件、既存の環境、問題の説明などの情報が表示されます。ケーススタディに[すべての情報]タブがある場合、表示される情報は後続のタブに表示される情報と同じであることに注意してください。質問に答える準備ができたら、[質問]ボタンをクリックして質問に戻ります。
概要
あなたは、米国の質の高い私有および商業用不動産を専門とする会社であるFabrikamResidencesのデータサイエンティストです。Fabrikam Residencesはヨーロッパへの進出を検討しており、ヨーロッパの主要都市の個人住宅の価格を調査するように依頼しました。
Azure Machine Learning Studioを使用して、プロパティの中央値を測定します。線形回帰モジュールとベイズ線形回帰モジュールを使用して、不動産価格を予測する回帰モデルを作成します。
データセット
ロンドンとパリの2つの都市のプロパティの詳細を含む、CSV形式の2つのデータセットがあります。両方のファイルを別々のデータセットとしてAzureMachineLearning Studioに追加し、実験の開始点にします。両方のデータセットには、次の列が含まれています。
最初の調査では、データセットの構造はMedianValue列を除いて同一であることが示されています。
小さいパリのデータセットにはテキスト形式のMedianValueが含まれていますが、大きいロンドンのデータセットには数値形式のMedianValueが含まれています。
データの問題
欠落している値
両方のデータセットのAccessibilityToHighway列に欠落している値が含まれています。欠落しているデータは、欠落している値を入力する前に、データ内の他の変数を使用して条件付きでモデル化されるように、新しいデータに置き換える必要があります。
各データセットの列には、欠落している値とnull値が含まれています。データセットには、多くの外れ値も含まれています。Age列には、外れ値の割合が高くなっています。Age列に外れ値がある行を削除する必要があります。
MedianValue列とAvgRoomsInHouse列は、どちらも数値形式のデータを保持します。2つの列の関係をより詳細に分析するには、特徴選択アルゴリズムを選択する必要があります。
モデルフィット
モデルは過剰適合の兆候を示しています。過剰適合を減らす、より洗練された回帰モデルを作成する必要があります。
実験要件
パフォーマンスを評価するには、線形回帰モジュールとベイズ線形回帰モジュールを相互検証するように実験を設定する必要があります。いずれの場合も、データセットの予測子はMedianValueという名前の列です。ParisデータセットのMedianValue列のデータ型が、Londonデータセットの構造と一致していることを確認する必要があります。
結果を予測するには、データの列に優先順位を付ける必要があります。関係を測定するには、ノンパラメトリック統計を使用する必要があります。
MediaValue列とAvgRoomsinHouse列の間の関係を分析するには、特徴選択アルゴリズムが必要です。
モデルトレーニング
順列特徴の重要性
訓練されたモデルとテストデータセットが与えられた場合、特徴変数の順列特徴重要度スコアを計算する必要があります。モデルの絶対適合を決定する必要があります。
ハイパーパラメータ
学習フェーズを高速化するには、モデル学習プロセスでハイパーパラメータを構成する必要があります。さらに、この構成では、各評価間隔で最もパフォーマンスの低い実行をキャンセルする必要があります。これにより、成功する可能性が高いモデルに労力とリソースが振り向けられます。
モデルがハイパーパラメータ調整で計算リソースを効率的に使用しない可能性があることを懸念しています。また、モデルによって全体的なチューニング時間の増加が妨げられる可能性があることも懸念されます。したがって、有望な仕事を終わらせることなく節約を提供するモデルに早期打ち切り基準を実装する必要があります。
テスト
Azure MachineLearningStudioのPartitionandSampleモジュールを使用したサンプリングに基づいて、データセットの複数のパーティションを作成する必要があります。
相互検証
相互検証のために、3つの等しいパーティションを作成する必要があります。また、テストデータセットとトレーニングデータセットの行が各都市の主要な川の近くにあるプロパティによって均等に分割されるように、交差検定プロセスを構成する必要があります。データがサンプリングプロセスを通過する前に、このタスクを完了する必要があります。
線形回帰モジュール
線形回帰モジュールをトレーニングするときは、モデルで使用するのに最適な機能を決定する必要があります。機能重要度プロセスが完了する前後のパフォーマンスを測定するために提供される標準メトリックを選択できます。複数のトレーニングモデル間での機能の分散は一貫している必要があります。
データの視覚化
テスト結果をFabrikamResidencesチームに提供する必要があります。結果の提示を支援するためにデータの視覚化を作成します。
モデルの診断テスト評価を実行するには、受信者動作特性(ROC)曲線を作成する必要があります。2クラスのDecisionForestモジュールと2クラスのDecisionJungleモジュールを相互に比較するには、AzureLearningStudioでROC曲線を作成するための適切な方法を選択する必要があります。

- 質問一覧「157問」
- 質問1 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問2 AzureMachineLearningワークスペースから実行される実験を取得す...
- 質問3 Azure Machine Learningサービスを使用して、training.dataとい...
- 質問4 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問5 AzureのWindowsおよびLinux用のデータサイエンス仮想マシン(DSV...
- 質問6 AzureMachineLearningワークスペースを作成します。 次の要件を...
- 質問7 AzureMachineLearningのHyperdrive機能を使用してモデルをトレー...
- 質問8 モデルトレーニング要件に適した早期停止基準を実装する必要があ
- 質問9 モデルのトレーニング要件に従って、順列特徴重要度モジュールを
- 質問10 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問11 Azure Machine Learning Studioを使用して、機械学習実験を構築...
- 質問12 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問13 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問14 あなたは分類タスクに取り組んでいます。学生がサッカーをしたい
- 質問15 データセットの構造が一致するように、メタデータの編集モジュー
- 質問16 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問17 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問18 二項分類を実行するためにリカレントニューラルネットワークを構
- 質問19 機械学習モデルを作成しています。 データ内の外れ値を特定する
- 質問20 次の形式のsalesDataという名前のPythonデータフレームがありま...
- 質問21 CSVファイルからテキストを前処理することを計画しています。Azu...
- 質問22 Azure ML SDKを使用して実験を実行する準備をしており、コンピュ...
- 質問23 Azure Machine Learning Serviceを使用して、ニューラルネットワ...
- 質問24 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問25 Azure Machine Learningを使用して、dataset1という名前のデータ...
- 質問26 150を超える機能を含むデータセットがあります。データセットを...
- 質問27 イベント中の呼び出し数を推定する回帰モデルを構築しています。
- 質問28 クレジットカード詐欺の可能性のある事例を特定するために、銀行
- 質問29 DockerforWindowsを参加者に紹介するための実践的なワークショッ...
- 質問30 Azure Machine Learning Designerを使用して、回帰モデルのトレ...
- 質問31 あなたは線形回帰モデルを作成するデータサイエンティストです。
- 質問32 AzureMachineLearningワークスペースでモデルをトレーニングして...
- 質問33 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問34 Azure Machine Learningを使用して、モデルをリアルタイムWebサ...
- 質問35 Azure ML SDKを使用して、バッチ推論パイプラインを作成します。...
- 質問36 ラベル付けされた写真のセットを使用するマルチクラスの画像分類
- 質問37 分類タスクを解決しています。 k分割交差検定を使用して、限られ...
- 質問38 K-meansアルゴリズムを使用してクラスタリングを実行しています...
- 質問39 Azure Machine Learningを使用して、機械学習モデルをトレーニン...
- 質問40 Azure Machine Learning Studioを使用して、2つのデータセットが...
- 質問41 既存のモデルを再トレーニングします。 モデルの現在のバージョ
- 質問42 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問43 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問44 x.1x2およびx3機能用のscikit-learnPythonライブラリを使用して...
- 質問45 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問46 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問47 一連のデータサイエンス実験用に、事前に構築された開発環境を選
- 質問48 ホテル予約Webサイトの不正取引を予測するための機械学習モデル...
- 質問49 Azure Machine Learning Studioを使用して、大規模なデータスト...
- 質問50 モデルのトレーニングに使用されるPythonコードを含むJupyterNot...
- 質問51 群集感情のローカルモデルの特徴エンジニアリング戦略を実装する
- 質問52 パフォーマンス曲線の展示に示されているように、広告応答モデル
- 質問53 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問54 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問55 音声認識ディープラーニングモデルを作成する予定です。 モデル
- 質問56 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問57 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問58 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問59 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問60 [年齢]列に外れ値が存在するかどうかを視覚的に識別し、外れ値を...
- 質問61 CSVファイルからテキストを前処理することを計画しています。Azu...
- 質問62 同僚は、次のコードを使用して、機械学習サービスワークスペース
- 質問63 都市の住宅販売データを含むデータセットがあります。データセッ
- 質問64 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問65 バイアスと分散の問題に対処するには、グローバルペナルティイベ
- 質問66 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問67 Azure MachineLearningStudioで重回帰モデルを作成しています。 ...
- 質問68 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問69 数人の学生に実践的なワークショップを提供する予定です。このワ
- 質問70 C-サポートベクター分類を使用して、不均衡なトレーニングデータ...
- 質問71 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問72 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問73 AzureMachineLearningのHyperdrive機能を使用してモデルをトレー...
- 質問74 短い文の形式で書かれた12,000件の顧客レビューを含むCSVファイ...
- 質問75 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問76 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問77 Azure MachineLearningStudioで実験を作成します-10.000行を含む...
- 質問78 組織は、ラベル付けされた写真のセットを使用するマルチクラスの
- 質問79 Azure MachineLearningStudioで実験を作成します。10,000行を含...
- 質問80 トレーニングエラー値と検証エラー値の間に大きな違いがあるモデ
- 質問81 x.1x2およびx3機能用のscikit-learnPythonライブラリを使用して...
- 質問82 データセットに対してフィルターベースの特徴選択を実行していま
- 質問83 広告レスポンスのモデリング戦略を定義する必要があります。 順
- 質問84 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問85 さまざまな都市の持ち家の人口統計データを調査する予定です。デ
- 質問86 ラベル付けされた写真のセットを使用するマルチクラスの画像分類
- 質問87 ラベル付けされた画像のセットを使用するマルチクラスの画像分類
- 質問88 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問89 二項分類を実行するためにリカレントニューラルネットワークを構
- 質問90 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問91 提供されているトレーニングセットを使用して、二項分類モデルを
- 質問92 あなたは、画像分類のための深い畳み込みニューラルネットワーク
- 質問93 AzureMachineLearningでリモートコンピューティングのトレーニン...
- 質問94 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問95 データの視覚化要件に従って、診断テスト評価用の視覚化を作成す
- 質問96 財務チームは、finance-dataという名前のAzureStorageBLOBコンテ...
- 質問97 フォルダを参照するcsvjolderという名前のファイルデータセット...
- 質問98 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問99 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問100 データの視覚化要件に従って、診断テスト評価用の視覚化を作成す
- 質問101 Azure Machine Learning Studioの2クラスニューラルネットワーク...
- 質問102 機械学習モデルをトレーニングします。 テスト用のリアルタイム
- 質問103 音声認識ディープラーニングモデルを作成する予定です。 モデル
- 質問104 自動機械学習を使用して回帰モデルをトレーニングすることを計画
- 質問105 ペナルティイベント検出のプロセスを定義する必要があります。
- 質問106 AccessibilityToHighway列の欠落データを置き換える必要がありま...
- 質問107 あなたのチームは、データエンジニアリングとデータサイエンスの
- 質問108 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問109 Azure MachineLearningStudioに時系列データセットがあります。 ...
- 質問110 デシジョンツリーアルゴリズムを使用しています。に等しい木の深
- 質問111 モデルトレーニング要件に合わせて、順列特徴重要度モジュールを
- 質問112 あなたは分類タスクに取り組んでいます。学生がサッカーをしたい
- 質問113 AzureMachineLearningデザイナーを使用してトレーニングパイプラ...
- 質問114 Azureを使用して機械学習、実験を開発しています。 次の画像は、...
- 質問115 AzureのWindowsおよびLinux用のデータサイエンス仮想マシン(DSV...
- 質問116 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問117 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問118 バイアスと分散の問題に対処するには、グローバルペナルティイベ
- 質問119 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問120 X、Y、およびZの数値機能を含む機能セットがあります。 X、Y、お...
- 質問121 分類モデルをトレーニングするデータを含むコンマ区切り値(CSV...
- 質問122 10,000個のデータポイントと150個の特徴を持つ正規化された数値...
- 質問123 ローカルモデルの特徴抽出戦略を構築する必要があります。 コー
- 質問124 テスト要件に従って、データを分割する方法を特定する必要があり
- 質問125 あなたはワイナリーでデータサイエンティストとして雇われていま
- 質問126 人が病気にかかっているかどうかを予測するために、二項分類モデ
- 質問127 デシジョンツリーアルゴリズムを使用しています。に等しい木の深
- 質問128 CPUベースのコンピューティングクラスターとAzureKubernetesServ...
- 質問129 モデルをトレーニングするためのAzureMachineLearningコンピュー...
- 質問130 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問131 Azure Machine Learning Serviceを使用して、ニューラルネットワ...
- 質問132 Azure MachineLearningStudioで実験を作成します-10.000行を含む...
- 質問133 あなたは銀行で働いているデータサイエンティストであり、Azure ...
- 質問134 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問135 Windows用のディープラーニング仮想マシンを構成します。 以下を...
- 質問136 あなたはホテル予約ウェブサイト会社で働いているデータサイエン
- 質問137 STANDARD_D1仮想マシンイメージを使用して、ComputeOneという名...
- 質問138 Python言語を使用して、グローバルペナルティ検出モデルのサンプ...
- 質問139 トレーニングクラスターと推論クラスターを含むAzureMachineLear...
- 質問140 群集感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問141 トレーニング済みのモデルをAzureMachineLearningワークスペース...
- 質問142 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問143 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問144 AzureMachineLearningで機械学習モデルをトレーニングしています...
- 質問145 数人の学生に実践的なワークショップを提供する予定です。このワ
- 質問146 Azure MachineLearningStudioを使用してバイナリ分類モデルを作...
- 質問147 あなたは、猫と犬を識別するために深層学習モデルを交配します。
- 質問148 次のバージョンのモデルを登録します。 (Exhibit) Azure ML Pyth...
- 質問149 英語のテキストコンテンツをフランス語のテキストコンテンツに翻
- 質問150 AzureMachineLearningサービスで機械学習モデルをトレーニングす...
- 質問151 AzureMachineLearningワークスペースを使用します。 Webサービス...
- 質問152 マルチクラスの画像分類深層学習モデルを作成します。 モデルは
- 質問153 Azure MachineLearningStudioで分類タスクを実行しています。 提...
- 質問154 AzureMachineLearningワークスペースで自動機械学習実験を実行し...
- 質問155 ペナルティイベント検出のプロセスを定義する必要があります。
- 質問156 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問157 AccessibilityToHighway列の欠落データを置き換える必要がありま...
