- ホーム
- Microsoft
- AI-102 - Designing and Implementing a Microsoft Azure AI Solution
- Microsoft.AI-102.v2025-04-08.q286
- 質問91
有効的なAI-102問題集はJPNTest.com提供され、AI-102試験に合格することに役に立ちます!JPNTest.comは今最新AI-102試験問題集を提供します。JPNTest.com AI-102試験問題集はもう更新されました。ここでAI-102問題集のテストエンジンを手に入れます。
AI-102問題集最新版のアクセス
「425問、30% ディスカウント、特別な割引コード:JPNshiken」
スマート電子商取引プロジェクトを開発しています。
PDF のコンテンツを検索に含めるようにスキルセットを設計する必要があります。
スキルセット設計図はどのように完成させるべきでしょうか。答えるには、適切なサービスを正しいステージにドラッグします。各サービスは、1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。

PDF のコンテンツを検索に含めるようにスキルセットを設計する必要があります。
スキルセット設計図はどのように完成させるべきでしょうか。答えるには、適切なサービスを正しいステージにドラッグします。各サービスは、1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。
正解:
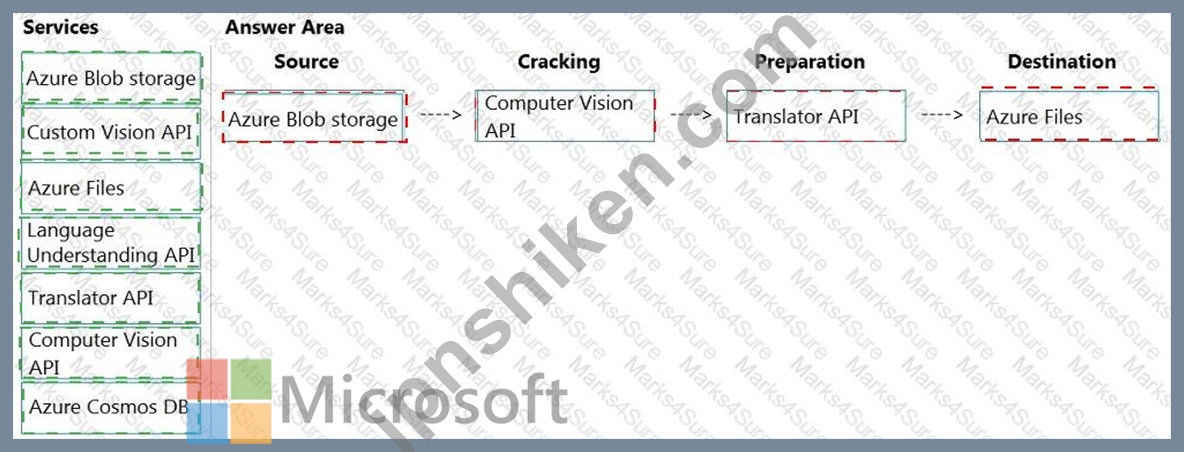
Explanation:

ボックス 1: Azure Blob ストレージ
パイプラインの開始時には、非構造化テキストまたは非テキスト コンテンツ (画像、スキャンされたドキュメント、JPEG ファイルなど) があります。データは、インデクサーがアクセスできる Azure データ ストレージ サービスに存在している必要があります。
ボックス 2: コンピュータ ビジョン API
シナリオ: 製品に関連付けられた画像、マニュアル、ビデオから得られた洞察を検索する機能をユーザーに提供します。
Computer Vision Read API は、画像や複数ページの PDF ドキュメントから印刷されたテキスト (複数の言語)、手書きのテキスト (英語のみ)、数字、通貨記号を抽出する Azure の最新の OCR テクノロジ (新機能について学ぶ) です。
ボックス3: 翻訳API
シナリオ: 製品の説明、トランスクリプト、およびすべてのテキストは、英語、スペイン語、ポルトガル語で利用できる必要があります。
ボックス 4: Azure ファイル
シナリオ: 生成されたすべての生の洞察データを保存し、後でデータを処理できるようにします。
参照:
https://docs.microsoft.com/en-us/azure/search/cognitive-search-concept-intro
https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/overview-ocr

- 質問一覧「286問」
- 質問1 Azure AI を使用して、ユーザーが性的に露骨な画像を共有するの...
- 質問2 Face API の呼び出しを開発しています。呼び出しでは、employeef...
- 質問3 会話型言語理解を使用して言語モデルを構築します。言語モデルは
- 質問4 チャットボットの要件を満たすために QnA Maker リソースを構築...
- 質問5 タスク追跡をサポートするチャットボットを構築する予定です。 l...
- 質問6 技術的なポッドキャストの文字起こしサービスを構築しています。
- 1コメント質問7 カスタム Form Recognizer モデルを構築します。 次の表に示すよ...
- 質問8 CS1 という名前の Azure Al Content Safety リソースを含む Azur...
- 質問9 Docker コンテナで実行される Language Understanding ソリュー...
- 質問10 Computer Vision API の呼び出しから取得された結果を検証するた...
- 質問11 Azure Cognitive Search カスタム スキルを構築しています。 次...
- 質問12 次の方法を使用して、Azure AI サービス リソースをプロビジョニ...
- 質問13 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問14 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問15 CS1 という名前の Azure Al Content Safety リソースを含む Azur...
- 質問16 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問17 何千もの画像を含むライブラリがあります。 画像に写真、図面、
- 質問18 Face API を使用するアプリケーションを開発します。 人物グルー...
- 質問19 Al1 という名前の Azure OpenAl リソースと User1 という名前の...
- 質問20 チャットボットの要件を満たすために QnA Maker リソースを構築...
- 質問21 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問22 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問23 チャットボットを構築しています。 性的に露骨な表現を含むメッ
- 質問24 PDF ファイルとして保存されたプレス リリースのコレクションが...
- 質問25 Computer Vision API の呼び出しから取得された結果を検証するた...
- 質問26 チャットボットの設計を確認しています。チャットボットには、次
- 質問27 外出先でのショッピング プロジェクトを開発しています。 チャッ...
- 質問28 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問29 アプリケーションの Text Analytics 出力を調べています。 分析...
- 質問30 非リレーショナルデータベースの特徴は何ですか?
- 質問31 次の各文について、正しい場合は「はい」を選択してください。正
- 質問32 Computer Vision API の呼び出しから取得された結果を検証するた...
- 質問33 Face API の呼び出しを開発しています。呼び出しでは、employeef...
- 質問34 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問35 それぞれ独自の言語理解モデルを持つチャットボットが 100 個あ...
- 質問36 あなたは製品作成プロジェクトを計画しています。 ビデオを分析
- 質問37 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問38 チャットボットで使用する会話フローを設計しています。 Microso...
- 質問39 米国西部 Azure リージョンでホストされている contoso1 という...
- 質問40 アプリケーションの Text Analytics 出力を調べています。 分析...
- 質問41 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問42 フィードバックを管理するアプリがあります。 Azure Cognitive S...
- 質問43 あなたは製品作成プロジェクトを計画しています。 多言語の製品
- 質問44 オブジェクト検出を実行する Custom Vision サービス プロジェク...
- 質問45 Azure Al とカスタム トレーニングされた分類子を使用して画像内...
- 質問46 次の各文について、正しい場合は「はい」を選択してください。正
- 質問47 言語理解を使用するボットを構築しています。 次の内容を含む LU...
- 質問48 発信者の母国語で応答できる自動通話処理システムを開発する必要
- 質問49 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問50 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問51 遠隔地の学習者向けにインターネットベースのトレーニング ソリ
- 質問52 AI Language カスタム質問回答サービスを使用するアプリがありま...
- 質問53 Azure Cognitive Search を使用してナレッジベースを開発してい...
- 質問54 Computer Vision API の呼び出しから取得された結果を検証するた...
- 質問55 スマート e コマース プロジェクトを開発しています。Cognitive ...
- 質問56 感情分析と光学式文字認識 (OCR) を実行するために使用する新し...
- 質問57 テキスト処理ソリューションを開発しています。 次の方法を開発
- 質問58 Speech SDK と MP3 エンコーディングを使用するストリーミング音...
- 質問59 Face API の呼び出しを開発しています。呼び出しでは、employeef...
- 質問60 あなたは製品作成プロジェクトを計画しています。 多言語の製品
- 質問61 Microsoft Bot Framework Composer を使用してチャットボットを...
- 質問62 Azure サービスをアーキテクチャ内の適切な場所に一致させます。...
- 質問63 英語(イギリス)で行われた講義を録画するサービスを開発してい
- 質問64 スマート電子商取引プロジェクトを開発しています。 Cognitive S...
- 質問65 顧客サポート チャットボットを構築しています。 次のものを識別...
- 質問66 O で、音声翻訳を実行する App1 というアプリを開発します。 英...
- 質問67 顧客サポート チャットボットを構築しています。 次のものを識別...
- 質問68 Microsoft Bot Framework SDK を使用して、Microsoft Teams チャ...
- 質問69 受信メールを処理し、メール メッセージをフランス語または英語
- 質問70 Azure Al Anomaly Detector サービスを使用する監視ソリューショ...
- 質問71 次の構成の Azure サブスクリプションがあります。 * サブスクリ...
- 質問72 AH という名前の Azure OpenA1 リソースを含む Azure サブスクリ...
- 質問73 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問74 チャットボットを構築しています。 性的に露骨な表現を含むメッ
- 質問75 次の図に示すように、ユーザーに情報を提供するチャットボットを
- 質問76 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問77 米国西部 Azure リージョンでホストされている contoso1 という...
- 質問78 次のコマンドを実行します。 (Exhibit) 次の各文について、正し...
- 質問79 テキスト分析に使用される Azure Cognitive Services サービスの...
- 質問80 Language Understanding ポータルを使用して Language Understan...
- 質問81 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問82 テキストを含む 50,000 件のスキャンされたドキュメントのコレク...
- 質問83 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問84 Microsoft Bot Framework SDK を使用して、Microsoft Teams チャ...
- 質問85 カスタム Form Recognizer モデルを構築します。 次の表に示すよ...
- 質問86 あなたの会社では、アップロードされた画像内の顔を検出するため
- 質問87 外出先でのショッピング プロジェクトを開発しています。 QnA Ma...
- 質問88 Azure Cognitive Search を使用してナレッジベースを開発してい...
- 質問89 カスタム Form Recognizer モデルを構築します。 次の表に示すよ...
- 質問90 O で、音声翻訳を実行する App1 というアプリを開発します。 英...
- 質問91 スマート電子商取引プロジェクトを開発しています。 PDF のコン...
- 質問92 テキスト処理ソリューションを開発しています。 次の方法を開発
- 質問93 Microsoft Bot Framework を使用して構築され、Azure にデプロイ...
- 質問94 電子商取引チャットボット用の言語理解モデルを構築しています。
- 質問95 次の構成の Azure サブスクリプションがあります。 * サブスクリ...
- 質問96 次の構成の Azure サブスクリプションがあります。 * サブスクリ...
- 質問97 JavaScript でボットを構築します。 Azure コマンド ライン イン...
- 質問98 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問99 食品を生産する工場を所有しています。 個人用保護具 (PPE) 要件...
- 質問100 iOS アプリで使用されるモデルを構築しています。 猫と犬の画像...
- 質問101 遠隔地の学習者向けにインターネットベースのトレーニング ソリ
- 質問102 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問103 All という名前の Azure OpenAI リソースと CS1 という名前の Az...
- 質問104 製品作成プロジェクト用に画像をアップロードするためのコードを
- 質問105 テスト用ローカル デバイスとオンプレミス データセンターで、コ...
- 質問106 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問107 工場の生産ラインで製造されたコンポーネントの欠陥を認識するア
- 質問108 Translator API を使用するアプリケーションのメソッドを開発し...
- 質問109 Azure Cognitive Search を使用する Web アプリがあります。 ア...
- 質問110 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問111 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問112 Azure Cognitive Search を使用するエンリッチメント パイプライ...
- 質問113 Speech SDK を使用してアプリを構築しています。このアプリは、...
- 質問114 テキスト処理ソリューションを開発しています。 以下に示す機能
- 質問115 チャットボットで使用する会話フローを設計しています。 Microso...
- 質問116 次の要件を満たすチャットボットを構築する必要があります。 雑
- 質問117 Microsoft Bot Framework Composer を使用してチャットボットを...
- 質問118 感情分析と光学式文字認識 (OCR) を実行するために使用する新し...
- 質問119 Azure Cognitive Search を使用する Web アプリがあります。 ア...
- 質問120 テキスト分析に使用される Azure Cognitive Services サービスの...
- 質問121 スマート電子商取引プロジェクトを開発しています。 PDF のコン...
- 質問122 Video Indexer サービスを使用して社内会議のビデオを表示する W...
- 質問123 次の図に示すように、Microsoft Bot Framework Composer を使用...
- 質問124 Azure サービスをアーキテクチャ内の適切な場所に一致させます。...
- 質問125 チャットボットを開発しています。 次のコンポーネントを作成し
- 質問126 プログラムで Azure Cognitive Services リソースを作成するため...
- 質問127 感情分析と光学式文字認識 (OCR) を実行するために使用する新し...
- 質問128 テキストを含む 50,000 件のスキャンされたドキュメントのコレク...
- 質問129 注文のステータスに関する顧客からの電話に応答するアプリを構築
- 質問130 次の図に示すように、ユーザーに情報を提供するチャットボットを
- 質問131 英語(イギリス)で行われた講義を録画するサービスを開発してい
- 質問132 カスタム Form Recognizer モデルを構築します。 次の表に示すよ...
- 質問133 ビデオ トレーニング ソリューション用のコンテンツを作成してい...
- 質問134 Azure Cognitive Search を使用するエンリッチメント パイプライ...
- 質問135 テキスト分析に使用される Azure Cognitive Services サービスの...
- 質問136 ユーザー画像を共有するアプリを構築しています。 次の要件を満
- 質問137 アプリケーションの Text Analytics 出力を調べています。 分析...
- 質問138 次の JSON を使用して、Azure Cognitive Search のナレッジ スト...
- 質問139 Computer Vision クライアント ライブラリを使用するアプリケー...
- 質問140 Microsoft Bot Framework SDK を使用してチャットボットを構築し...
- 質問141 開発環境に acvdev という名前の Custom Vision リソースがあり...
- 質問142 コンテナーにデプロイされている app1 という名前の Language Un...
- 質問143 Azure Al Anomaly Detector サービスを使用する監視ソリューショ...
- 質問144 機密文書をスキャンし、言語サービスを使用して内容を分析するア
- 質問145 Azure OpenA1 リソースを含む Azure サブスクリプションがあり、...
- 質問146 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問147 学生がエッセイの参考文献を見つけるために使用するソリューショ
- 質問148 自然言語処理を使用して、ソーシャル メディアでのブランドの一
- 質問149 テキスト処理ソリューションを開発しています。 以下に示す機能
- 質問150 受信メールを処理し、メール メッセージをフランス語または英語
- 質問151 アプリケーションの言語サービス出力を調べています。 分析され
- 質問152 次の図に示すように、Microsoft Bot Framework Composer を使用...
- 質問153 外出先でのショッピング プロジェクトを開発しています。 QnA Ma...
- 質問154 Docker コンテナで実行される Language Understanding ソリュー...
- 質問155 Azure Cosmos DB API を適切なデータ構造に一致させます。 回答...
- 質問156 PDF ファイルとして保存されたプレス リリースのコレクションが...
- 質問157 次の各文について、正しい場合は「はい」を選択してください。そ
- 質問158 Face API を使用して、サンプル画像に基づいて人物の写真を検索...
- 質問159 ビデオ トレーニング ソリューション用のコンテンツを作成してい...
- 質問160 ユーザーの自然言語入力を理解するために、会話型言語理解モデル
- 質問161 Azure Video Indexer サービスを使用するアプリを構築しています...
- 質問162 小売ドメインを使用して、会社の製品を識別する Custom Vision ...
- 質問163 Web ベースの顧客エージェントのユーザーからの自然言語入力を処...
- 質問164 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問165 工場の生産ラインで製造されたコンポーネントの欠陥を認識するア
- 質問166 次の方法を使用して、Azure Cognitive Services リソースをプロ...
- 質問167 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問168 次の図に示すように、Microsoft Bot Framework Composer を使用...
- 質問169 それぞれ独自の言語理解モデルを持つチャットボットが 100 個あ...
- 質問170 Microsoft Bot Framework SDK を使用してボットを構築します。 ...
- 質問171 テスト用ローカル デバイスとオンプレミス データセンターで、コ...
- 質問172 Azure Cosmos DB API を適切なデータ構造に一致させます。 回答...
- 質問173 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問174 Azure Al コンテンツ セーフティ リソースを含む Azure サブスク...
- 質問175 開発環境に acvdev という名前の Custom Vision リソースがあり...
- 質問176 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問177 あなたは製品作成プロジェクトを計画しています。 ビデオを分析
- 質問178 画像内のオブジェクトを検出するモデルを構築しています。 トレ
- 質問179 Azure Cognitive Search を使用する Web アプリがあります。 ア...
- 質問180 オブジェクト検出を実行する Custom Vision サービス プロジェク...
- 質問181 チャットボットを開発しています。 次のコンポーネントを作成し
- 質問182 フランス語とドイツ語を話す発信者からの電話を受信する通話処理
- 質問183 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問184 それぞれ独自の言語理解モデルを持つチャットボットが 100 個あ...
- 質問185 それぞれ独自の言語理解モデルを持つチャットボットが 100 個あ...
- 質問186 顧客は Azure Cognitive Search を使用します。 顧客は、サーバ...
- 質問187 Face API を使用して、サンプル画像に基づいて人物の写真を検索...
- 質問188 オブジェクト検出を実行する Custom Vision サービス プロジェク...
- 質問189 発信者の母国語で応答できる自動通話処理システムを開発する必要
- 質問190 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問191 顧客サポート チャットボットを構築しています。 次のものを識別...
- 質問192 感情分析と光学式文字認識 (OCR) を実行するために使用する新し...
- 質問193 英語からスペイン語にテキストを翻訳する、App1 という名前の Az...
- 質問194 カスタム Azure OpenAI モデルがあります。 次の表に示すファイ...
- 質問195 Microsoft Bot Framework SDK を使用して、Microsoft Teams チャ...
- 質問196 iOS アプリで使用されるモデルを構築しています。 猫と犬の画像...
- 質問197 チャットボットの設計を確認しています。チャットボットには、次
- 質問198 Azure Al とカスタム トレーニングされた分類子を使用して画像内...
- 質問199 コンテナーにデプロイされている app1 という名前の Language Un...
- 質問200 プログラムで Azure Cognitive Services リソースを作成するため...
- 質問201 Appl という名前の Azure App Service アプリを含む Azure サブ...
- 質問202 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問203 あなたは製品作成プロジェクトを計画しています。 多言語の製品
- 質問204 ローカル ドライブに保存されている、file1.avi という名前の 20...
- 質問205 モバイル アプリで使用される Custom Vision モデルをトレーニン...
- 質問206 Face API を使用して、サンプル画像に基づいて人物の写真を検索...
- 質問207 A1 GPT 3.5 モデルの 3 つのデプロイメントをホストする AH とい...
- 質問208 Face API を使用するアプリケーションを開発します。 人物グルー...
- 質問209 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問210 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問211 外出先でのショッピング プロジェクトを開発しています。 QnA Ma...
- 質問212 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問213 あなたは製品作成プロジェクトを計画しています。 ビデオを分析
- 質問214 Speech SDK と MP3 エンコーディングを使用するストリーミング音...
- 質問215 タスク追跡をサポートするチャットボットを構築する予定です。 I...
- 質問216 チャットボットの要件を満たすために QnA Maker リソースを構築...
- 質問217 Azure Al Video Indexer アカウントを含む Azure サブスクリプシ...
- 質問218 O で、音声翻訳を実行する App1 というアプリを開発します。 英...
- 質問219 Azure Al Language サービスを使用して機密性の高い顧客データを...
- 質問220 iOS アプリで使用されるモデルを構築しています。 猫と犬の画像...
- 質問221 Azureサブスクリプションをお持ちの場合 ユーザーのプロンプトに...
- 質問222 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問223 URL からアクセスできる領収書があります。 Form Recognizer と ...
- 質問224 コンテナーにデプロイされている app1 という名前の Language Un...
- 質問225 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問226 Azure Cognitive Service for Language でカスタムの質問応答プ...
- 質問227 Speech SDK と MP3 エンコーディングを使用するストリーミング音...
- 質問228 自然言語モデルを構築しています。 アクティブラーニングを有効
- 質問229 Azure Cognitive Service for Language の質問応答を使用するチ...
- 質問230 Speech SDK を使用してアプリを構築しています。このアプリは、...
- 質問231 次の各文について、正しい場合は「はい」を選択してください。正
- 質問232 O で、音声翻訳を実行する App1 というアプリを開発します。 英...
- 質問233 AH という名前の Azure OpenAI リソースを含む Azure サブスクリ...
- 質問234 小売ドメインを使用して、会社の製品を識別する Custom Vision ...
- 質問235 ソーシャル メディア メッセージでブランドに対する一般の認識を...
- 質問236 ドイツ語の Microsoft Word 文書と PowerPoint プレゼンテーショ...
- 質問237 Azure Cognitive Search カスタム スキルを構築しています。 次...
- 質問238 Computer Vision クライアント ライブラリを使用するメソッドを...
- 質問239 電子商取引プラットフォーム用の言語理解モデルを構築しています
- 質問240 英語(イギリス)で行われた講義を録画するサービスを開発してい
- 質問241 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問242 ユーザーが画像をアップロードできるようにするアプリを構築して
- 質問243 テキスト処理ソリューションを開発しています。 以下に示す機能
- 質問244 ドイツ語の Microsoft Word 文書と PowerPoint プレゼンテーショ...
- 質問245 カスタム ニューラル音声を使用する小売キオスク システムを構築...
- 質問246 チケットを購入するための言語理解モデルを構築しています。 Pur...
- 質問247 次の構成の Azure サブスクリプションがあります。 * サブスクリ...
- 質問248 Azure Cognitive Search を使用するエンリッチメント パイプライ...
- 質問249 次の図に示すように、ユーザーに情報を提供するチャットボットを
- 質問250 Azureサブスクリプションをお持ちの場合 ユーザーのプロンプトに...
- 質問251 画像内のオブジェクトを検出するモデルを構築しています。 トレ
- 質問252 テキスト分析に使用される Azure Cognitive Services サービスの...
- 質問253 コンテナーにデプロイされている app1 という名前の Language Un...
- 質問254 特定の企業名が言及されているかどうかを識別するには、ビデオ
- 質問255 URL の配列からナレッジ ベースを作成する Azure Webblob を構築...
- 質問256 英語(イギリス)で行われた講義を録画するサービスを開発してい
- 質問257 Speech SDK と MP3 エンコーディングを使用するストリーミング音...
- 質問258 Microsoft Bot Framework SDK を使用してチャットボットを構築し...
- 質問259 英語からスペイン語にテキストを翻訳する、App1 という名前の Az...
- 質問260 一般向け Web サイトからのビデオとテキストを処理する新しい販...
- 質問261 Computer Vision API の呼び出しから取得された結果を検証するた...
- 質問262 ドイツ語の Microsoft Word 文書と PowerPoint プレゼンテーショ...
- 質問263 カスタム Form Recognizer モデルを構築します。 次の表に示すよ...
- 質問264 チャットボットの設計を確認しています。チャットボットには、次
- 質問265 Azure Cosmos DB API を適切なデータ構造に一致させます。 回答...
- 質問266 感情分析と光学式文字認識 (OCR) を実行するために使用する新し...
- 質問267 CS1 という名前の Azure Al Content Safety リソースを含む Azur...
- 質問268 iOS アプリで使用されるモデルを構築しています。 猫と犬の画像...
- 質問269 Microsoft Bot Framework SDK を使用して、Microsoft Teams チャ...
- 質問270 Azure Cognitive Service for Language に質問回答プロジェクト...
- 質問271 次のコマンドを実行します。 (Exhibit) 次の各文について、正し...
- 質問272 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問273 テスト用ローカル デバイスとオンプレミス データセンターで、コ...
- 質問274 画像内のオブジェクトを検出するモデルを構築しています。 トレ
- 質問275 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問276 複数のアプリで使用される Search 1 という名前の Azure Cogniti...
- 質問277 QnA Maker サービスを使用する小売チャットボットを構築していま...
- 質問278 チケットを購入するための言語理解モデルを構築しています。 Pur...
- 質問279 Azure OpenAI を使用して応答を生成するチャットボットがありま...
- 質問280 次のコマンドを実行します。 (Exhibit) 次の各文について、正し...
- 質問281 Docker コンテナで実行される Language Understanding ソリュー...
- 質問282 チケットを購入するための言語理解モデルを構築しています。 Pur...
- 質問283 QnA Maker アプリケーションを使用するチャットボットがあります...
- 質問284 Azure サービスをアーキテクチャ内の適切な場所に一致させます。...
- 質問285 All という名前の Azure OpenAI リソースと User1 という名前の...
- 質問286 プログラムで Azure Cognitive Services リソースを作成するため...
