有効的なDP-200問題集はJPNTest.com提供され、DP-200試験に合格することに役に立ちます!JPNTest.comは今最新DP-200試験問題集を提供します。JPNTest.com DP-200試験問題集はもう更新されました。ここでDP-200問題集のテストエンジンを手に入れます。
DP-200問題集最新版のアクセス
「242問、30% ディスカウント、特別な割引コード:JPNshiken」
あなたの会社は、Twitterからのストリーミングデータを処理するイベント処理エンジンを作成することを計画しています。
データエンジニアリングチームは、Azure EventHubsを使用してストリーミングデータを取り込みます。
Azure Databricksを使用して、Azure EventHubsからストリーミングデータを受信するソリューションを実装する必要があります。
順番に実行することをお勧めする3つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。
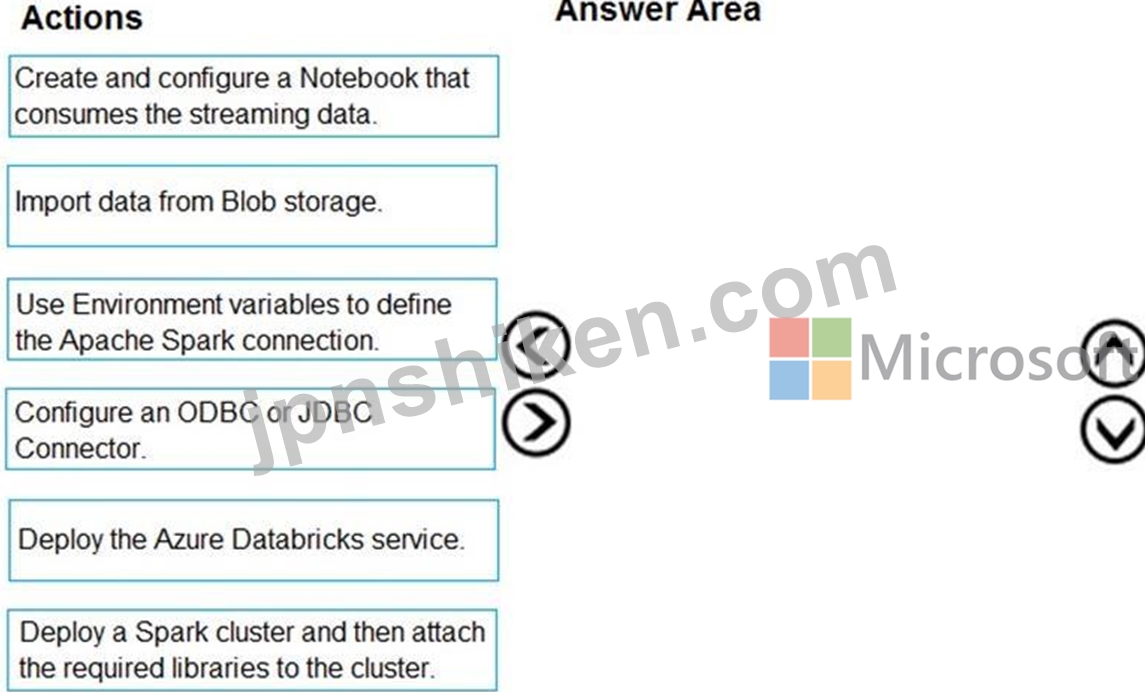
データエンジニアリングチームは、Azure EventHubsを使用してストリーミングデータを取り込みます。
Azure Databricksを使用して、Azure EventHubsからストリーミングデータを受信するソリューションを実装する必要があります。
順番に実行することをお勧めする3つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。
正解:
説明

手順1:AzureDatabricksサービスをデプロイする
Azure Databricks Serviceをセットアップして、AzureDatabricksワークスペースを作成します。
ステップ2:Sparkクラスターをデプロイしてから、必要なライブラリーをクラスターに接続します。
DatabricksでSparkクラスターを作成するには、Azureポータルで、作成したDatabricksワークスペースに移動し、[ワークスペースの起動]を選択します。
ライブラリをSparkクラスターにアタッチします。TwitterAPIを使用してツイートをイベントハブに送信します。また、Apache Spark Event Hubsコネクターを使用して、Azure EventHubsへのデータの読み取りと書き込みを行います。これらのAPIをクラスターの一部として使用するには、これらのAPIをライブラリとしてAzure Databricksに追加し、Sparkクラスターに関連付けます。
ステップ3:ストリーミングデータを消費するノートブックを作成して構成します。
DatabricksワークスペースにReadTweetsFromEventhubという名前のノートブックを作成します。
ReadTweetsFromEventHubは、イベントハブからツイートを読み取るために使用するコンシューマーノートブックです。
参照:
https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs

- 質問一覧「164問」
- 質問1 シミュレーション (Exhibit) 必要に応じて、次のログイン資格情...
- 質問2 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問3 会社のデータエンジニアリングソリューションを開発します。アプ
- 質問4 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問5 必要に応じて、次のログイン資格情報を使用します。 Azureユーザ...
- 質問6 Tier10データ用にAzureData FactoryJSON定義をセットアップする...
- 質問7 会社は、Microsoft Azure SQLDatabaseを使用して会社の機密デー...
- 質問8 Azure SQL Data Warehouseが割り当てられた最大のリソースを消費...
- 質問9 ティア1データをマスクする必要があります。どの関数を使用する
- 質問10 次のAzureStreamAnalyticsクエリがあります。 (Exhibit) 次の各...
- 質問11 会社のデータエンジニアリングソリューションを開発します。さら
- 質問12 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問13 AzureSynapseにSQLプールがあります。 一部のクエリが失敗するか...
- 質問14 PipelineAとPipelineBという名前の2つのパイプラインを持つAzure...
- 質問15 レースコントロールのテレメトリデータを収集するためのソリュー
- 質問16 財務計算データ分析プロセスを管理します。Microsoft Azure仮想...
- 質問17 必要に応じて、次のログイン資格情報を使用します。 Azureユーザ...
- 質問18 あなたの会社は、Twitterからのストリーミングデータを処理する...
- 質問19 Microsoft AzureSQLデータベースの新しい単一データベースインス...
- 質問20 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問21 Azure Data Lake StorageGen2の何千ものCSVファイルにデータが保...
- 質問22 DataFactoryを使用してSSISプロセスを置き換える必要があります...
- 質問23 Monitor&Manageアプリを使用して、Azureデータファクトリを監視...
- 質問24 会社のデータエンジニアリングソリューションを開発します。 Mic...
- 質問25 ある会社は、Platform-as-a-Service(PaaS)を使用して新しいデ...
- 質問26 会社は、カスタムソリューションを使用して、オンプレミスのMicr...
- 質問27 MicrosoftAzureでLambdaアーキテクチャを使用してソリューション...
- 質問28 ある会社がサービスベースのデータ環境を展開しています。このデ
- 質問29 Azure Stream Analyticsジョブを構築して、ユーザーがWebページ...
- 質問30 ある会社は、地理空間データの複数のセットのバッチ処理を実行す
- 質問31 ある会社が、データとオンプレミスのMicrosoft SQLServerデータ...
- 質問32 ある会社が、アプリケーションのデータストアとしてMicrosoft Az...
- 質問33 次の表に示すリソースを含むAzureサブスクリプションがあります...
- 質問34 厳密なユーザーアクセス制御でMicrosoftAzureSQLデータベースイ...
- 質問35 あなたはデータアーキテクトです。データエンジニアリングチーム
- 質問36 会社のデータエンジニアリングソリューションを開発します。 プ
- 質問37 あなたはデータエンジニアです。Hadoop分散ファイルシステム(HD...
- 質問38 Azure Data Lake StorageGen2の何千ものCSVファイルにデータが保...
- 質問39 あなたの会社は、Elasticプールで構成されたMicrosoft AzureSQL...
- 質問40 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問41 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問42 24時間ごとに100,000JSONを書き込むAzureCosmosDBデータベースを...
- 質問43 Microsoft Azure StreamAnalyticsを使用してイベント処理ソリュ...
- 質問44 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問45 Database1という名前のAzureSQLデータベースと、HubAおよびHubB...
- 質問46 Azure DataFactoryパイプラインをデプロイできることを確認する...
- 質問47 あなたはデータアーキテクトです。データエンジニアリングチーム
- 質問48 電話ベースのポーリングデータアップロードの信頼性要件が満たさ
- 質問49 電話ベースのポーリングデータアップロードの信頼性要件が満たさ
- 質問50 Azure DataFactoryを使用してAzureStorageアカウントとAzureSQL...
- 質問51 会社には、オンプレミスのMicrosoft SQLServerインスタンスがあ...
- 質問52 次の表に示すリソースを含むAzureサブスクリプションがあります...
- 質問53 あなたは、MicrosoftAzureにラムダアーキテクチャを実装するデー...
- 質問54 基幹業務アプリケーションをサポートするデータベースのセキュリ
- 質問55 会社のデータエンジニアリングソリューションを開発します。さら
- 質問56 必要に応じて、次のログイン資格情報を使用します。 Azureユーザ...
- 質問57 会社のデータエンジニアリングソリューションを開発します。 会
- 質問58 DataFactoryを使用してSSISプロセスを置き換える必要があります...
- 質問59 データマスキング要件を満たすために、各列にどのマスキング関数
- 質問60 データマスキング要件を満たすために、各列にどのマスキング関数
- 質問61 シミュレーション 必要に応じて、次のログイン資格情報を使用し
- 質問62 一貫性のあるJSONドキュメントを生成するには、StreamAnalytics...
- 質問63 Azure Active Directory(Azure AD)統合を使用してAzure Data L...
- 質問64 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問65 組織が管理する暗号化キーを使用するAzureCosmosDBアカウントを...
- 質問66 Tier10データ用にAzureData FactoryJSON定義をセットアップする...
- 質問67 AzureDatabricksで1日1回バッチ処理を実行することを計画してい...
- 質問68 ある会社は、Azure SQL Databaseを使用して、ミッションクリティ...
- 質問69 各US2リージョンにDB1という名前のAzureSQLデータベースがありま...
- 質問70 Azure StreamAnalytics関数を実装しています。 要件ごとにどのウ...
- 質問71 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問72 財務計算データ分析プロセスを管理します。Microsoft Azure仮想...
- 質問73 Tier10データ用にAzureData FactoryJSON定義をセットアップする...
- 質問74 あなたの会社はAzureSQLデータベースとAzureBlobストレージを使...
- 質問75 シミュレーション (Exhibit) 必要に応じて、次のログイン資格情...
- 質問76 展示に示されているシグナルロジックを使用するAzureSynapseのSQ...
- 質問77 基幹業務アプリケーションをサポートするデータベースのセキュリ
- 質問78 SALESDBの暗号化を実装する必要があります。 順番に実行する必要...
- 質問79 データ移動の要件を満たすには、Azure DataFactoryパイプライン...
- 質問80 あなたはグローバルな小売企業向けのデータプラットフォームを開
- 質問81 Azure Synapse Analyticsに、Server1という名前のサーバー上のDW...
- 質問82 AzureDatabricks環境とAzureStorageアカウントを含むAzureサブス...
- 質問83 Azure Active Directory(Azure AD)統合を使用してAzure Data L...
- 質問84 AzureDatabricksで1日1回バッチ処理を実行することを計画してい...
- 質問85 Contoso、Ltd。は、Azure SQLDatabaseを使用するように既存のア...
- 質問86 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問87 毎日、会社は数百のファイルをAzure BlobStorageとAzureData Lak...
- 質問88 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問89 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問90 Azure Data Lake StorageGen2アカウントへのアクセスを提供する...
- 質問91 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問92 あなたの会社は、Twitterからのストリーミングデータを処理する...
- 質問93 Tier7およびTier8パートナーのAzureSQLデータベースへのアクセス...
- 質問94 あなたの会社は、Elasticプールで構成されたMicrosoft AzureSQL...
- 質問95 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問96 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問97 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問98 電話ベースのポーリングデータがPollingDataデータベースで分析...
- 質問99 会社は、カスタムソリューションを使用して、オンプレミスのMicr...
- 質問100 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問101 会社には、オンプレミスのMicrosoft SQLServerインスタンスがあ...
- 質問102 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問103 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問104 会社のデータエンジニアリングソリューションを開発します。 IoT...
- 質問105 ある企業は、Microsoft Azure Stream Analyticsを使用して、ソー...
- 質問106 毎日、会社は数百のファイルをAzure BlobStorageとAzureData Lak...
- 質問107 電話ベースのポーリングデータがPollingDataデータベースで分析...
- 質問108 あなたの会社はAzureSQLデータベースとAzureBlobストレージを使...
- 質問109 会社のMicrosoftAzureDatabricks環境を管理します。プライベート...
- 質問110 Azure Stream Analyticsを使用して、Azure Event HubsからTwitte...
- 質問111 あなたは、数テラバイトの地理空間データを視覚化するソリューシ
- 質問112 Azure SQL Data Warehouseが割り当てられた最大のリソースを消費...
- 質問113 あなたはデータエンジニアです。Hadoop分散ファイルシステム(HD...
- 質問114 会社は、カスタムソリューションを使用して、オンプレミスのMicr...
- 質問115 必要に応じて、次のログイン資格情報を使用します。 Azureユーザ...
- 質問116 各US2リージョンにDB1という名前のAzureSQLデータベースがありま...
- 質問117 あなたの会社は、Elasticプールで構成されたMicrosoft AzureSQL...
- 質問118 会社のデータエンジニアリングソリューションを開発します。アプ
- 質問119 DataFactoryを使用してSSISプロセスを置き換える必要があります...
- 質問120 会社のデータエンジニアリングソリューションを開発します。 IoT...
- 質問121 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問122 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問123 会社は、カスタムソリューションを使用して、オンプレミスのMicr...
- 質問124 Azure Stream Analyticsを使用して、Azure Event HubsからTwitte...
- 質問125 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問126 必要に応じて、次のログイン資格情報を使用します。 Azureユーザ...
- 質問127 アプリケーションは、データソリューションとしてMicrosoft Azur...
- 質問128 Tier7およびTier8パートナーのAzureSQLデータベースへのアクセス...
- 質問129 DataFactoryを使用してSSISプロセスを置き換える必要があります...
- 質問130 ある会社は、Platform-as-a-Service(PaaS)を使用して新しいデ...
- 質問131 Azure DataWarehouseに1GB未満のディメンションテーブルを作成す...
- 質問132 テレメトリデータに適切なRU / sを特定するために使用する必要が...
- 質問133 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問134 電話ベースのポーリングデータがPollingDataデータベースで分析...
- 質問135 基幹業務アプリケーションをサポートするデータベースのセキュリ
- 質問136 会社のデータエンジニアリングソリューションを開発します。 プ
- 質問137 一貫性のあるJSONドキュメントを生成するには、StreamAnalytics...
- 質問138 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問139 Azure Synapse Analyticsに、FactOnlineSalesという名前のテーブ...
- 質問140 Azure DataFactoryパイプラインをデプロイできることを確認する...
- 質問141 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問142 新しいAzureDataFactory環境があります。 実行期間の傾向を特定...
- 質問143 Azure Data Lake StorageGen2の何千ものCSVファイルにデータが保...
- 質問144 ある会社が、Microsoft SQLServerをオンプレミスで使用してMicro...
- 質問145 Azure SynapseAnalyticsでエンタープライズデータウェアハウスを...
- 質問146 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問147 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問148 会社には、オンプレミスのMicrosoft SQLServerインスタンスがあ...
- 質問149 レースコントロールのテレメトリデータを収集するためのソリュー
- 質問150 Employeeという名前のテーブルを含むAzureSQLデータベースがあり...
- 質問151 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問152 AzureSynapseにSQLプールがあります。 AzureBlobストレージから...
- 質問153 ある会社が、Microsoft SQLServerをオンプレミスで使用してMicro...
- 質問154 技術的な要件を満たすために、リアルタイム処理を監視する必要が
- 質問155 MicrosoftAzureで新しいLambdaアーキテクチャを設計しています。...
- 質問156 (Exhibit) 必要に応じて、次のログイン資格情報を使用します。 A...
- 質問157 財務計算データ分析プロセスを管理します。Microsoft Azure仮想...
- 質問158 MicrosoftAzureでマネージドデータウェアハウスソリューションを...
- 質問159 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問160 AzureSQLデータベースに自動調整モードを実装しています。 自動...
- 質問161 AzureDatabricks環境とAzureStorageアカウントを含むAzureサブス...
- 質問162 ある会社には、エラスティックプールを備えたAzureSQLデータベー...
- 質問163 ポーリングデータのセキュリティ要件が満たされていることを確認
- 質問164 会社のデータエンジニアリングソリューションを開発します。アプ
