- ホーム
- Microsoft
- DP-203J - Data Engineering on Microsoft Azure (DP-203日本語版)
- Microsoft.DP-203J.v2023-10-09.q139
- 質問48
有効的なDP-203J問題集はJPNTest.com提供され、DP-203J試験に合格することに役に立ちます!JPNTest.comは今最新DP-203J試験問題集を提供します。JPNTest.com DP-203J試験問題集はもう更新されました。ここでDP-203J問題集のテストエンジンを手に入れます。
DP-203J問題集最新版のアクセス
「365問、30% ディスカウント、特別な割引コード:JPNshiken」
CSV ファイルからデータを取り込み、指定された種類のデータに列をキャストし、Azure Synapse Analytic 専用 SQL プールのテーブルにデータを挿入する Azure Data Factory データ フローを作成しています。 CSV ファイルには、ユーザー名、コメント、および日付という 3 つの列が含まれています。
データフローにはすでに次のものが含まれています。
ソース変換。
適切なタイプのデータを設定するための派生列変換
a.
データをプールに入れるためのシンク変換。
データ フローが次の要件を満たしていることを確認する必要があります。
すべての有効な行を宛先テーブルに書き込む必要があります。
コメント列の切り捨てエラーは、積極的に回避する必要があります。
挿入時に切り捨てエラーが発生するコメント値を含む行は、BLOB ストレージ内のファイルに書き込む必要があります。
どの2つのアクションを実行する必要がありますか?それぞれの正解は、ソリューションの一部を示しています。
注: 正しい選択ごとに 1 ポイントの価値があります。
データフローにはすでに次のものが含まれています。
ソース変換。
適切なタイプのデータを設定するための派生列変換
a.
データをプールに入れるためのシンク変換。
データ フローが次の要件を満たしていることを確認する必要があります。
すべての有効な行を宛先テーブルに書き込む必要があります。
コメント列の切り捨てエラーは、積極的に回避する必要があります。
挿入時に切り捨てエラーが発生するコメント値を含む行は、BLOB ストレージ内のファイルに書き込む必要があります。
どの2つのアクションを実行する必要がありますか?それぞれの正解は、ソリューションの一部を示しています。
注: 正しい選択ごとに 1 ポイントの価値があります。
正解:A,B
Explanation
B: Example:
1. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
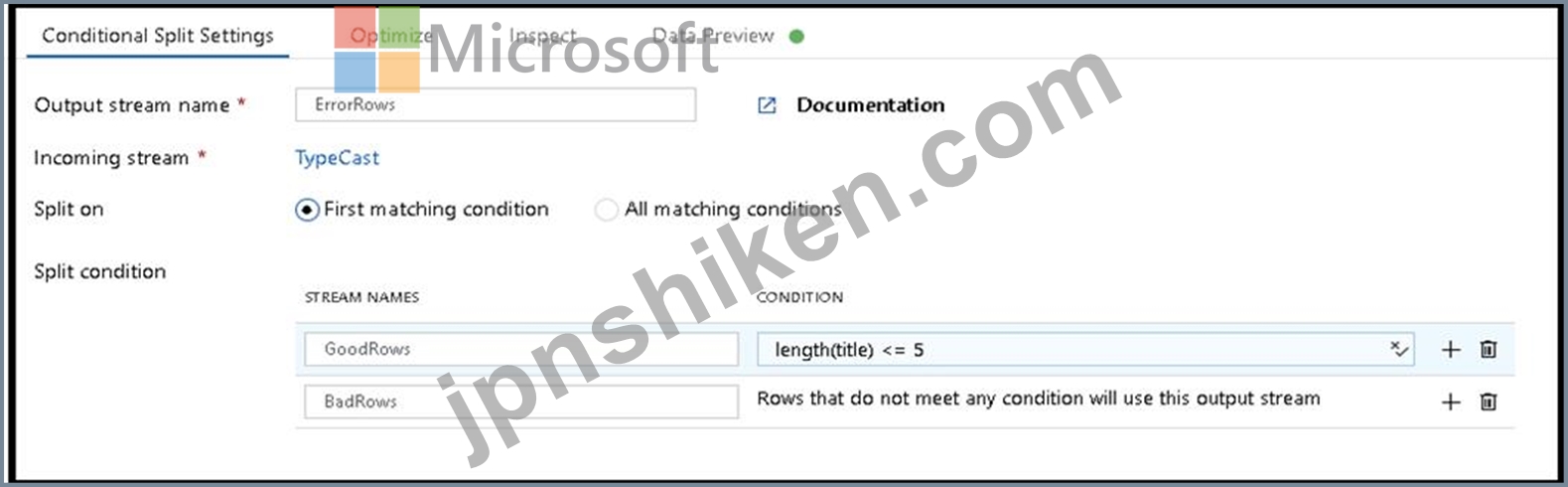
2. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
A:
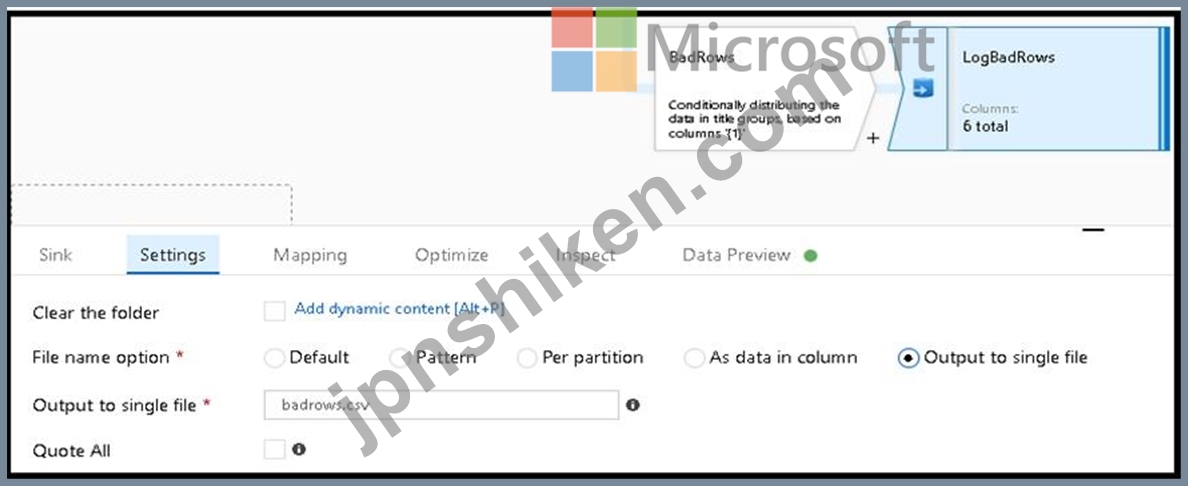
3. Now we need to log the rows that failed. Add a sink transformation to the BadRows stream for logging.
Here, we'll "auto-map" all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file output to a single file in Blob Storage. We'll call the log file "badrows.csv".
4. The completed data flow is shown below. We are now able to split off error rows to avoid the SQL truncation errors and put those entries into a log file. Meanwhile, successful rows can continue to write to our target database.
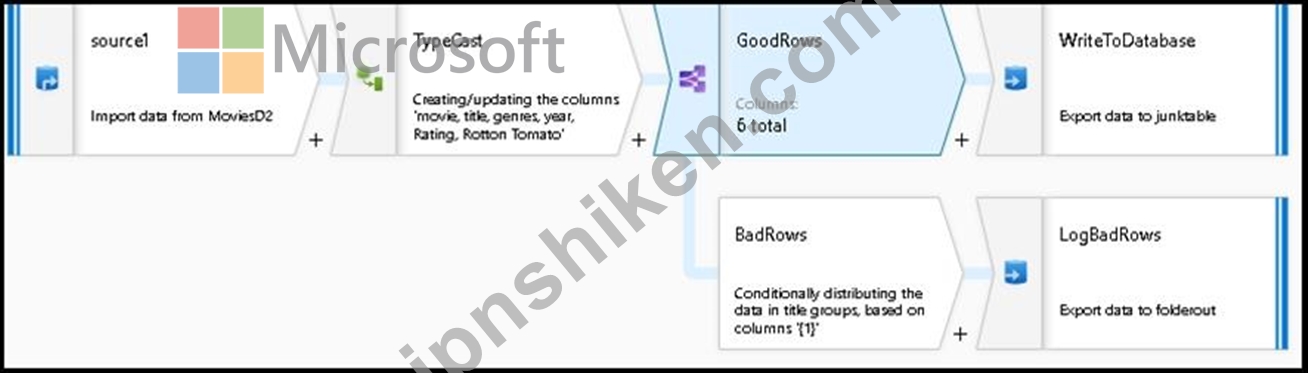
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-data-flow-error-rows
B: Example:
1. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
2. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
A:
3. Now we need to log the rows that failed. Add a sink transformation to the BadRows stream for logging.
Here, we'll "auto-map" all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file output to a single file in Blob Storage. We'll call the log file "badrows.csv".
4. The completed data flow is shown below. We are now able to split off error rows to avoid the SQL truncation errors and put those entries into a log file. Meanwhile, successful rows can continue to write to our target database.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-data-flow-error-rows

- 質問一覧「139問」
- 質問1 Azure Synapse Analytics 専用 SQL プールにテーブルをバッチで...
- 質問2 Azureサブスクリプションがあります。 ステージングテーブルを含...
- 質問3 DB1 という名前の Azure SQL データベースと、pipeline という名...
- 質問4 AzureDatabricksで1日1回バッチ処理を実行することを計画してい...
- 質問5 Azure Synapse サーバーレス SQL プールがあります。 OPENROWSET...
- 質問6 次の図に示すように、Git リポジトリ設定を持つ Azure データ フ...
- 質問7 さまざまな量のデータを取り込むストリーミングデータソリューシ
- 質問8 Azure Synapse Analytics 専用の SQL プールがあります。 データ...
- 質問9 リアルタイム データ処理ソリューションの高可用性を向上させる
- 質問10 寄木細工の形式でバッチデータセットを実装しています。 データ
- 質問11 Azure Synapse に SQL プールがあります。 ユーザーは、プールに...
- 質問12 Azureサブスクリプションがあります。 Azure Data Lake Storage ...
- 質問13 AzureSynapseにSQLプールがあります。 一部のクエリが失敗するか...
- 質問14 16 個のパーティションを持つ、retailhub という名前の Azure イ...
- 質問15 Sales という名前の外部テーブルを含む、Pool1 という名前の Azu...
- 質問16 Azure Blob Storage アカウントに保存されている Parquet ファイ...
- 質問17 ジオゾーン冗長ストレージ(GZRS)を導入する高可用性Azure Data...
- 質問18 Folder と Folder2 という名前の 2 つのフォルダーを含む Azure ...
- 質問19 AzureStorageアカウントに格納されているデータのクエリインター...
- 質問20 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問21 Sales.Orders という名前のテーブルを含む Azure Synapse Analyt...
- 質問22 トランザクションデータの分析ストレージソリューションを設計す
- 質問23 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問24 ある会社は、侵入検知データを分析するために Apache Spark 分析...
- 質問25 あなたは、会社の人事 (HR) 部門と運用部門のデータを保存するた...
- 質問26 次のリソースを含むAzureサブスクリプションがあります。 Group1...
- 質問27 AzureSynapseにSQLプールがあります。 AzureBlobストレージから...
- 質問28 Azure Stream Analytics ジョブを監視しています。 過去 1 時間...
- 質問29 Azure Active Directory(Azure AD)統合を使用して、Azure Data...
- 質問30 Pool1という名前のAzureSynapse Analytics ApacheSparkプールが...
- 質問31 Table1 という名前のテーブルを含む Azure Synapse Analytics 専...
- 質問32 Azure サブスクリプションがあります。 ステージング テーブルと...
- 質問33 Pool1 という Azure Synapse Analytics サーバーレス SQL プール...
- 質問34 重要な顧客の連絡先情報を保護するために何を使用することをお勧
- 質問35 2020年上半期のトランザクションのファクトテーブルを含むAzureS...
- 質問36 DW1という名前のAzureSynapseAnalyticsのエンタープライズデータ...
- 質問37 CSV ファイルを含む Azure Data Lake Storage Gen2 コンテナーを...
- 質問38 ある企業は、Platform-as-a-Service(PaaS)を使用して新しいデ...
- 質問39 Azure SynapseAnalyticsワークスペースを設計しています。 保存...
- 質問40 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問41 Azure Synapse Analytics 専用 SQL プールでディメンション テー...
- 質問42 Azure Synapse Analytics のエンタープライズ データ ウェアハウ...
- 質問43 Azure Data Lake Gen2 ストレージ アカウントを実装する予定です...
- 質問44 R を主要言語としてサポートするが、Scale と SOL もサポートす...
- 質問45 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問46 Azure Synapse Analytics 専用の SQL プールで FactPurchase と...
- 質問47 Azure SynapseAnalyticsにデータウェアハウスがあります。 デー...
- 質問48 CSV ファイルからデータを取り込み、指定された種類のデータに列...
- 質問49 Azure Synapse Analytics で Apache Spark プールを使用して、Az...
- 質問50 オンライン注文のレコードを含むデータセットのスタースキーマを
- 質問51 Pool1という名前のAzureSynapseAnalytics専用のSQLプールがあり...
- 質問52 あなたは、企業向けのデータ エンジニアリング ソリューションを...
- 質問53 統合パイプラインにバージョン管理された変更を実装する必要があ
- 質問54 Azure Databricks リソースがあります。 Databricks リソースの...
- 質問55 DB1 という名前の Azure SQL データベースと storage1 という名...
- 質問56 あなたは、ペタバイト規模の医用画像データを保存するアプリケー
- 質問57 ユーザーがAzureSynapseAnalyticsサーバーレスSQLプールからAzur...
- 質問58 ADF1という名前のAzureData Factoryインスタンスと、WS1およびWS...
- 質問59 workspace1 という名前の Azure Synapse Analytics ワークスペー...
- 質問60 新しいファイルが Azure Data Lake Storage Gen2 コンテナーに到...
- 質問61 Dataflow1 という名前のデータ フロー アクティビティを含む Pip...
- 質問62 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問63 Pool1という名前のApacheSparkプールを含むWS1という名前のAzure...
- 質問64 Azure Synapse Analytics 専用 SQL プールにスター スキーマを実...
- 質問65 Azure Event Hubからのストリーミングデータを処理し、そのデー...
- 質問66 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問67 毎日 200,000 個の新しいファイルを生成する Azure ストレージ ...
- 質問68 毎日200,000個の新しいファイルを生成するAzureStorageアカウン...
- 質問69 大規模なファクト テーブルを含む Azure Synapse Analytics 専用...
- 質問70 storage1 という名前の Azure Data Lake Storage Gen2 アカウン...
- 質問71 Azure Databricks クラスターを作成し、インストールする追加の...
- 質問72 ジオゾーン冗長ストレージ(GZRS)を含む高可用性Azure Data Lak...
- 質問73 Azure Data Factory パイプラインを構築して、Azure Data Lake S...
- 質問74 ある会社には、MicrosoftAzureでホストされているリアルタイムの...
- 質問75 Azure Synapse Analytics 専用 SQL プール内のファクト テーブル...
- 質問76 分析ワークロードで使用するために raw JSON ファイルを変換する...
- 質問77 account1 と account2 という名前の 2 つの Azure Blob Storage ...
- 質問78 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問79 Azure Databricksを使用して、DBTBL1という名前のデータセットを...
- 質問80 Trigger1 というタンブリング ウィンドウ トリガーによって呼び...
- 質問81 ワークスペースという名前の Azure Databricks ワークスペースが...
- 質問82 あなたは、インターネットに接続するリモート センサーからのス
- 質問83 Azure DatabricksでPySparkを使用して、次のJSON入力を解析しま...
- 質問84 Azure イベント ハブからインスタント メッセージング データを...
- 質問85 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問86 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問87 料金所を通過する車両からのストリーミングデータを処理していま
- 質問88 Litware オンプレミス ネットワークの外部のユーザーが分析デー...
- 質問89 次の表に示すように、ログを保存するaccount1という名前のAzure ...
- 質問90 mytestdb という名前の Apache Spark データベースを含む MyWork...
- 質問91 Twitterフィード用のデータ取り込みおよびストレージソリューシ...
- 質問92 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールと...
- 質問93 Tablet という名前の Delta Lake ディメンション テーブルを含む...
- 質問94 次の図に示す Azure Synapse Analytics パイプラインがあります...
- 質問95 Azure Stream Analytics のウィンドウ関数を実装しています。 要...
- 質問96 あなたは、500 台の車両の監視ソリューションを設計しています。...
- 質問97 会社の次の 3 つの部門のデータを処理するための Azure Data Fac...
- 質問98 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールと...
- 質問99 Azure Synapse Analytics 専用の SQL プールにテーブルがありま...
- 質問100 Table1 という名前のテーブルを含む、SA1 という名前の Azure Sy...
- 質問101 Azure Synapse Analytics 専用の SQL ポッドがある。 専用 SQL ...
- 質問102 顧客用のJSONファイルを含むAzureData Lake StorageGen2アカウン...
- 質問103 Azure Event Hubsから受信したデータを処理し、Azure Data Lake ...
- 質問104 databricks1 という名前の Azure Databricks ワークスペースと s...
- 質問105 Azure Synapse Analytics 専用の SQL プールがあります。 PDW_SH...
- 質問106 Azure Active Directory (Azure AD) 統合を使用して Azure Data ...
- 質問107 Group1 という名前のセキュリティ グループを含む Azure Active ...
- 質問108 あなたは、小売環境のセンサーからの受信イベントを処理する Azu...
- 質問109 Azure SynapseAnalyticsでエンタープライズデータウェアハウスを...
- 質問110 Webサイト分析システムから、ダウンロード、リンククリック、フ...
- 質問111 Azure Data Factory を使用して、Azure Synapse Analytics サー...
- 質問112 Azure StreamAnalyticsジョブを監視しています。 バックログ入力...
- 質問113 Azure Data Lake Storage Gen2 アカウントへのソース データの増...
- 質問114 Azure Synapseに、dbo.Customersという名前のテーブルを含むSQL...
- 質問115 Azure Synapse Analytics 専用 SQL プール内のファクト テーブル...
- 質問116 Azure Data Lake Storage Gen2 のデプロイを計画しています。 デ...
- 質問117 ADFdev と ADFprod という 2 つの Azure Data Factory インスタ...
- 質問118 温度という名前の Apache Spark DataFrame があります。データの...
- 質問119 Azureデータファクトリがあります。 最後の180フレイからのパイ...
- 質問120 Pool1という名前のAzureSynapse Analytics専用SQLプールと、DB1...
- 質問121 MP1 という名前の Microsoft Purview アカウント、DF1 という名...
- 質問122 ws1 という名前の Azure Synapse Analytics ワークスペースと Co...
- 質問123 AzureSynapseAnalyticsで1GB未満のディメンションテーブルを作成...
- 質問124 ステージングゾーンを含むAzureDataLakeストレージアカウントが...
- 質問125 Azure Synapse データベース テンプレートを使用して、レイク デ...
- 質問126 PL1 という名前のパイプラインを含む DF1 という名前の Azure Fa...
- 質問127 Azure Event Hubs からのほぼリアルタイムのデータで独自のカス...
- 質問128 Database1 という名前の Azure SQL データベースと、HubA と Hub...
- 質問129 Azure Data Lake StorageGen2アカウントへのアクセスを提供する...
- 質問130 監視と管理アプリを使用して Azure データ ファクトリを監視する...
- 質問131 Azure Synapse Analytics 専用の SQL プールで販売トランザクシ...
- 質問132 Azure Synapse Analyticsで、スタースキーマにWebサイトのトラフ...
- 質問133 ユーザーが Web ページの機能を操作するために費やす時間を特定...
- 質問134 Azure Synapse Analytics 専用 SQL プールを含む Azure サブスク...
- 質問135 Azure Synapse Analytics専用のSQLプールで、製品カテゴリデータ...
- 質問136 Azure Synapse Analytics 専用の SQL プールを作成する予定です...
- 質問137 仮想ネットワークによって保護されているadls2という名前のAzure...
- 質問138 ハイブリッドAzureActive Directory(Azure AD)テナントにリン...
- 質問139 次の展示に示すように、Azure DataFactoryインスタンスのバージ...
