- ホーム
- Microsoft
- DP-100J - Designing and Implementing a Data Science Solution on Azure (DP-100日本語版)
- Microsoft.DP-100J.v2025-09-04.q209
- 質問103
有効的なDP-100J問題集はJPNTest.com提供され、DP-100J試験に合格することに役に立ちます!JPNTest.comは今最新DP-100J試験問題集を提供します。JPNTest.com DP-100J試験問題集はもう更新されました。ここでDP-100J問題集のテストエンジンを手に入れます。
DP-100J問題集最新版のアクセス
「508問、30% ディスカウント、特別な割引コード:JPNshiken」
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、指定された目標を達成する可能性のある独自のソリューションが含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象条件を予測するモデルを作成します。
データストアからデータを読み込み、処理されたデータを機械学習モデルのトレーニングスクリプトに渡すために、処理スクリプトを実行するパイプラインを作成する必要があります。
解決策:次のコードを実行します。
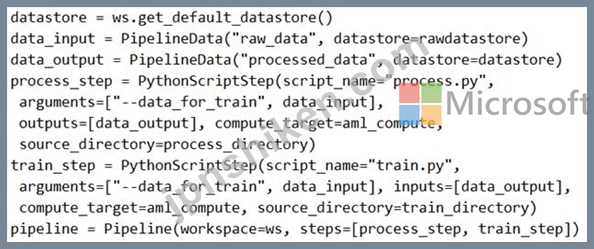
ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象条件を予測するモデルを作成します。
データストアからデータを読み込み、処理されたデータを機械学習モデルのトレーニングスクリプトに渡すために、処理スクリプトを実行するパイプラインを作成する必要があります。
解決策:次のコードを実行します。
ソリューションは目標を達成していますか?
正解:B
Note: Data used in pipeline can be produced by one step and consumed in another step by providing a PipelineData object as an output of one step and an input of one or more subsequent steps.
Compare with this example, the pipeline train step depends on the process_step_output output of the pipeline process step:
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import PythonScriptStep
datastore = ws.get_default_datastore()
process_step_output = PipelineData("processed_data", datastore=datastore) process_step = PythonScriptStep(script_name="process.py", arguments=["--data_for_train", process_step_output], outputs=[process_step_output], compute_target=aml_compute, source_directory=process_directory) train_step = PythonScriptStep(script_name="train.py", arguments=["--data_for_train", process_step_output], inputs=[process_step_output], compute_target=aml_compute, source_directory=train_directory) pipeline = Pipeline(workspace=ws, steps=[process_step, train_step]) Reference:
https://docs.microsoft.com/en-us/python/api/azureml-pipeline-core/azureml.pipeline.core.pipelinedata?
view=azure-ml-py
Compare with this example, the pipeline train step depends on the process_step_output output of the pipeline process step:
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import PythonScriptStep
datastore = ws.get_default_datastore()
process_step_output = PipelineData("processed_data", datastore=datastore) process_step = PythonScriptStep(script_name="process.py", arguments=["--data_for_train", process_step_output], outputs=[process_step_output], compute_target=aml_compute, source_directory=process_directory) train_step = PythonScriptStep(script_name="train.py", arguments=["--data_for_train", process_step_output], inputs=[process_step_output], compute_target=aml_compute, source_directory=train_directory) pipeline = Pipeline(workspace=ws, steps=[process_step, train_step]) Reference:
https://docs.microsoft.com/en-us/python/api/azureml-pipeline-core/azureml.pipeline.core.pipelinedata?
view=azure-ml-py

- 質問一覧「209問」
- 質問1 Azure Machine Learning ワークスペースのノートブックから、コ...
- 質問2 モデルのトレーニング要件に応じて早期停止基準を実装する必要が
- 質問3 Windows 用のディープ ラーニング仮想マシンを構成します。 次の...
- 質問4 AutoMLConfig クラスを使用して、最大 10 回のモデルトレーニン...
- 質問5 (Exhibit) 実験の実行完了後、Runオブジェクトのget_metricsメソ...
- 質問6 テスト要件に応じてデータを分割する方法を特定する必要がありま
- 質問7 バイナリ分類を実行するためにリカレント ニューラル ネットワー...
- 質問8 短い文章形式で記述された12,000件の顧客レビューを含むCSVファ...
- 質問9 Azure Machine Learning デザイナーを使用して機械学習ソリュー...
- 質問10 Azure Machine Learning ワークスペースを管理しています。ワー...
- 質問11 Azure Machine Learning SDK for Python を使用して、Azure Mach...
- 質問12 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問13 Azure Machine Learning ワークスペースがあります。ワークスペ...
- 質問14 (Exhibit) ワークスペース内のデータや実験を操作するには、Azur...
- 質問15 Azure Machine Learning SDK を使用して、分類モデルをトレーニ...
- 質問16 ある組織は Azure Machine Learning サービスを使用しており、機...
- 質問17 ノートブックからAzure ML Python SDK v2ベースのモデルをトレー...
- 質問18 Workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問19 Azure Machine Learning Studioを使用して、マルチクラス分類を...
- 質問20 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問21 Azure Machine Learning を使用して機械学習モデルを開発してい...
- 質問22 Azure Machine Learningをサポートするには、Azure Blob Storage...
- 質問23 バイオメディカル研究会社は、実験的な医療治療試験に人々を登録
- 質問24 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問25 自動車の価格データを含む Azure Machine Learning データセット...
- 質問26 Azure OpenAI サービス ベース モデルがデプロイされています。 ...
- 質問27 デザイナーを使用して新しい Azure Machine Learning パイプライ...
- 質問28 バイナリ分類モデルを作成します。モデルはAzure Machine Learni...
- 質問29 Azure Machine Learning ワークスペースを作成します。 プライベ...
- 質問30 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問31 深層学習モデルを開発して、半構造化、非構造化、および構造化デ
- 質問32 Azure Machine Learningモデルをトレーニングして登録します モ...
- 質問33 Azure Machine Learning ワークスペースがあります。ディープ ラ...
- 質問34 分類タスクを解決しています。 k分割交差検証を使用して、限られ...
- 質問35 広告応答のモデリング戦略を定義する必要があります。 順番に実
- 質問36 オープンソースの深層学習フレームワークCaffe2およびTheanoでDa...
- 質問37 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問38 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問39 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問40 Azure Machine Learning ワークスペースがあり、ローカルコンピ...
- 質問41 パイプラインを実行するPythonスクリプトがあります。このスクリ...
- 質問42 Azure Machine Learning Studio を使用してワークスペースを作成...
- 質問43 テスト要件に応じてデータを分割する方法を特定する必要がありま
- 質問44 パブリックエンドポイントからアクセスできる、workspace1 とい...
- 質問45 Azure Machine Learning ワークスペースを作成します。 実験のイ...
- 質問46 Azure Machine Learning ワークスペースを管理します。 再トレー...
- 質問47 Azure Machine Learning ワークスペースに複数の機械学習モデル...
- 質問48 Azure Machine Learning ワークスペースと新しい Azure DevOps ...
- 質問49 Azure Machine Learning ワークスペースを使用しています。モデ...
- 質問50 Workspace^ というAzure Machine Learningワークスペースがあり...
- 質問51 クリーニングが必要な生のデータセットを分析しています。 Azure...
- 質問52 Azure Machine Learning Studioを使用して機械学習実験を構築し...
- 質問53 Azureを使用して機械学習の実験を開発しています。次の画像は、...
- 質問54 音声認識の深層学習モデルを作成する予定です。 モデルはPython...
- 質問55 グローバル ペナルティ検出モデルのサンプリング戦略を構築する
- 質問56 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問57 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問58 Azure Al Foundry プロジェクトを管理します。 大規模言語モデル...
- 質問59 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問60 K-meansアルゴリズムを使用してクラスタリングを実行しています...
- 質問61 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問62 アルゴリズムのハイパーパラメータを調整しています。次の表は、
- 質問63 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問64 コンピューティングインスタンス「compute1」を持つAzure Machin...
- 質問65 次のコードを使用して、モデルをAzure Machine Learningリアルタ...
- 質問66 ワークスペースという名前のAzure Machine Learningワークスペー...
- 質問67 一連のCSVファイルには売上記録が含まれています。すべてのCSVフ...
- 質問68 Azure Machine Learning Designer を使用して、次のデータセット...
- 質問69 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問70 クラスAの100個のサンプルとクラスBの10,000個のサンプルを含む...
- 質問71 ラベル付き画像のセットを使用するマルチクラス画像分類の深層学
- 質問72 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問73 Azure Machine Learning デザイナーを使用してトレーニング パイ...
- 質問74 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問75 CSVファイルからテキストを前処理する予定です。Azure Machine L...
- 質問76 大規模な糖尿病患者グループの年齢情報を含むデータセットを分析
- 質問77 特徴抽出方法を選択する必要があります。 どちらの方法を使用す
- 質問78 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問79 モデルをトレーニングするために、Azure Machine Learning コン...
- 質問80 Azure Machine Learning ワークスペースがあり、スイープジョブ...
- 質問81 Azure Machine Learning ワークスペースを管理しています。サー...
- 質問82 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問83 機械学習モデルをトレーニングして登録します。モデルを使用して
- 質問84 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問85 機械学習実験をトレーニングするためのコンピューティング ター
- 質問86 外れ値を削除する前に、年齢列に外れ値が存在するかどうかを視覚
- 質問87 Azure Machine Learning を使用して、Bandit 早期終了ポリシーに...
- 質問88 Azure Machine Learning Studioの2クラスニューラルネットワーク...
- 質問89 Aunt Machine Learning を使用して機械学習モデルをトレーニング...
- 質問90 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問91 Azure Machine Learning Python SDK v2 のハイパーパラメータ調...
- 質問92 AmICompute クラスターとバッチ エンドポイントを含む Azure Mac...
- 質問93 分類タスクを解決しています。 データセットのバランスが崩れて
- 質問94 Azure Machine Learning Studioを使用して、バイナリ分類モデル...
- 質問95 Azure Machine Learning ワークスペースを作成します。 ワークス...
- 質問96 機械学習モデルを作成しています。 データ内の外れ値を特定する
- 質問97 Azure Machine Learning モデルを作成し、モデルファイルとスク...
- 質問98 Python SDK v2 を使用して、workspace1 という名前の Azure Mach...
- 質問99 Azure Machine Learning ワークスペースには、real_estate_data ...
- 質問100 Azure Machine Learning Studioを使用して、2つのデータセットが...
- 質問101 Azure Machine Learning ワークスペースを作成します。 DataDrif...
- 質問102 ペナルティ イベント検出のプロセスを定義する必要があります。 ...
- 質問103 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問104 Azure Al Foundryプロジェクトでチャットフローを開発する Jinja...
- 質問105 Azure Machine Learning ワークスペースを作成します。 次の要件...
- 質問106 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問107 分類モデルをトレーニングしたいデータを含むコンマ区切り値(CS...
- 質問108 Azure Machine Learning Studio を使用してバイナリ分類モデルを...
- 質問109 トレーニング クラスターと推論クラスターを含む Azure Machine ...
- 質問110 あなたは、鳥類の健康と渡りを追跡するプロジェクトのリードデー
- 質問111 Azure Machine Learning ワークスペースに保存されているデータ...
- 質問112 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問113 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問114 スクリプト実行構成を使用して、実験としてスクリプトを実行する
- 質問115 Azure Machine Learning 実験として Python スクリプトを実行す...
- 質問116 あなたは銀行で働いているデータサイエンティストであり、Azure ...
- 質問117 Azure Machine Learning ワークスペースを管理します。マシンチ...
- 質問118 機械学習モデルを作成しています。 null行を含むデータセットが...
- 質問119 ビジネスとデータの要件を満たす環境を選択する必要があります。
- 質問120 Azure Al Foundryプロジェクトを管理し、ベースモデルを微調整し...
- 質問121 Azure Machine Learning ワークスペースを管理します。Azure Mac...
- 質問122 ある組織が、ラベル付き写真のセットを使用する多クラス画像分類
- 質問123 複数の生徒に実践的なワークショップを実施する予定です。ワーク
- 質問124 地元のタクシー会社の履歴データを含むデータセットを分析し、回
- 質問125 CPU ベースのコンピューティング クラスターと Azure Kubernetes...
- 質問126 Azure Machine Learning データセットを作成します。Azure Machi...
- 質問127 デザイナを使用して、分類モデルのトレーニングパイプラインを作
- 質問128 Azure Machine Learning サービスを使用して、training.data と...
- 質問129 モデルのトレーニング要件に合わせて、順列特徴重要度モジュール
- 質問130 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問131 Azure Machine Learning ワークスペースがあります。 次のコード...
- 質問132 Workspace 1 Workspace! という名前の Azure Machine Learning ...
- 質問133 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問134 Azure Machine Learning サービスを使用するデータ サイエンス ...
- 質問135 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問136 STANDARD_D1 仮想マシン イメージを使用して、ComputeOne という...
- 質問137 イベント中の通話数を推定するための回帰モデルを構築しています
- 質問138 Azure Machine Learning プロジェクト ファイルを含む既存の Git...
- 質問139 Workspace 1 Workspace! という名前の Azure Machine Learning ...
- 質問140 Azure Machine Learning スタジオでノートブックを作成していま...
- 質問141 様々な都市における住宅所有に関する人口統計データを調査する予
- 質問142 次の Azure サブスクリプションと Azure Machine Learning サー...
- 質問143 ある人が病気にかかっているかどうかを予測するためのバイナリ分
- 質問144 Azure OpenAI サービスの基本モデルをデプロイしました。このモ...
- 質問145 Azure Machine Learning を使用して、Azure ML Python SDK v2 ベ...
- 質問146 Azure Machine Learning ワークスペースを管理します。 MLflow ...
- 質問147 x.1、x2、x3 機能に対して scikit-learn Python ライブラリを使...
- 質問148 Azure Machine Learning (ML) モデルがオンライン エンドポイン...
- 質問149 Azure Machine Learning Designerを使用して、トレーニングパイ...
- 質問150 Azure Machine Learning ワークスペースと、2 つの Azure Blob S...
- 質問151 マルチクラス画像分類ディープラーニング モデルを作成します。 ...
- 質問152 Pythonで機械学習モデルを作成しています。提供されたデータセッ...
- 質問153 Azure Machine Learning のトレーニング実験を実行します。トレ...
- 質問154 猫と犬を識別するためのディープラーニングモデルを構築していま
- 質問155 ノートブックからモデルをトレーニングするためのハイパーパラメ
- 質問156 機密データを含むデータセットがあります a。データセットを使用...
- 質問157 Azure Machine Learning ワークスペースから実行される実験を取...
- 質問158 モデルのトレーニングに使用されるPythonコードを含むJupyterNot...
- 質問159 150以上の特徴量を含むデータセットがあります。このデータセッ...
- 質問160 (Exhibit) 以下の各記述について、正しい場合は「はい」を選択し...
- 質問161 Azure Machine Learning ワークスペースを管理しています。既存...
- 質問162 Python SDK v2を使用して、Azure Machine Learningワークスペー...
- 質問163 Workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問164 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問165 Azure Machine Learning Studio を使用してワークスペースを作成...
- 質問166 ワークスペースという名前のAzure Machine Learningワークスペー...
- 質問167 Azure Machine Learning デザイナーを使用して実験を構築してい...
- 質問168 次のバージョンのモデルを登録します。 (Exhibit) Azure ML Pyth...
- 質問169 Azure Machine Learning ワークスペースを作成します。 ワークス...
- 質問170 同僚が次のコードを使用して、機械学習サービス ワークスペース
- 質問171 ある都市の住宅販売データを含むデータセットがあります。データ
- 質問172 ビジネス アプリケーションで使用されるバッチ推論パイプライン
- 質問173 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問174 英語のテキストコンテンツをフランス語のテキストコンテンツに翻
- 質問175 2 つの異なる年齢層内で糖尿病の陽性症例を予測するバイナリ分類...
- 質問176 Azure Machine Learning Designerを使用して、トレーニングパイ...
- 質問177 Azure Machine Learning ワークスペースを作成します。 Azure Ma...
- 質問178 ラベル付き写真セットを用いた多クラス画像分類ディープラーニン
- 質問179 Azure Machine Learning ワークスペースを使用します。Azure Dat...
- 質問180 パイプラインを実行するPythonスクリプトがあります。このスクリ...
- 質問181 Azure Machine Learning ワークスペースを管理しています。ノー...
- 質問182 Workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問183 ホテル予約ウェブサイトの不正取引を予測するための機械学習モデ
- 質問184 Azure Machine Learning ワークスペースがあります。 ワークスペ...
- 質問185 Azure Machine Learning ワークスペースを作成します。このワー...
- 質問186 Azure Storage BLOB コンテナー用に、ml-data というデータスト...
- 質問187 Azure Machine Learning を使用してモデルをトレーニングおよび...
- 質問188 決定木アルゴリズムを使用しています。木の深さが10で適切に一般...
- 質問189 WS1 という名前の Azure Machine Learning ワークスペースがあり...
- 質問190 モデルをトレーニングするときに、Azure Machine Learning の Hy...
- 質問191 銀行会社向けに、クレジットカード詐欺の可能性のある事例を特定
- 質問192 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問193 Azure Machine Learning で自動化された機械学習を使用して、マ...
- 質問194 gpt-4o-mini ベース モデルの Azure OpenAI サービスのデプロイ...
- 質問195 統計分布の非対称性を分析しています。 次の画像には、2 つのデ...
- 質問196 ML-workspaceという名前のAzureMachineLearningワークスペースを...
- 質問197 実験の要件とデータセットに基づいて、特徴ベースの特徴選択モジ
- 質問198 Python SDK v2 を使用して Azure Machine Learning ワークスペー...
- 質問199 Azure Machine Learning ワークスペースを使用します。 次の Pyt...
- 質問200 注: この問題は、同じシナリオを提示する一連の問題の一部です。...
- 質問201 AmICompute クラスターとバッチ エンドポイントを含む Azure Mac...
- 質問202 Git リポジトリを使用して、Azure Machine Learning ワークスペ...
- 質問203 機械学習モデルが、敏感な特徴にわたって不公平な予測を生成する
- 質問204 コンピューティング ターゲットとして Azure Data Science Virtu...
- 質問205 Azure Machine Learning ワークスペースを管理しています。scrip...
- 質問206 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問207 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問208 Azure Machine Learning Designer を使用して、次のデータセット...
- 質問209 次の Azure サブスクリプションと Azure Machine Learning サー...
