- ホーム
- Microsoft
- DP-100J - Designing and Implementing a Data Science Solution on Azure (DP-100日本語版)
- Microsoft.DP-100J.v2024-09-03.q196
- 質問62
有効的なDP-100J問題集はJPNTest.com提供され、DP-100J試験に合格することに役に立ちます!JPNTest.comは今最新DP-100J試験問題集を提供します。JPNTest.com DP-100J試験問題集はもう更新されました。ここでDP-100J問題集のテストエンジンを手に入れます。
DP-100J問題集最新版のアクセス
「528問、30% ディスカウント、特別な割引コード:JPNshiken」
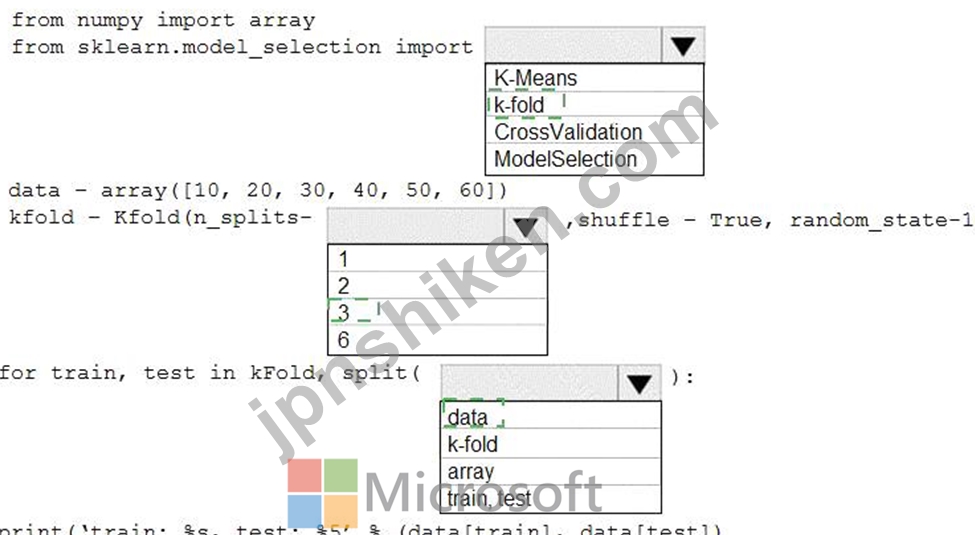
次のように定義された6つのデータポイントを含むPython NumPy配列を評価しています。
データ= [10、20、30、40、50、60]
Python Scikit-learn機械学習ライブラリのk-foldアルゴリズムの埋め込みを使用して、次の出力を生成する必要があります。
train: [10 40 50 60], test: [20 30]
train: [20 30 40 60], test: [10 50]
train: [10 20 30 50], test: [40 60]
出力を生成するには、相互検証を実装する必要があります。
どのようにコードセグメントを完成させるべきですか?回答するには、回答領域のダイアログボックスで適切なコードセグメントを選択します。
注:それぞれの正しい選択には1ポイントの価値があります。

データ= [10、20、30、40、50、60]
Python Scikit-learn機械学習ライブラリのk-foldアルゴリズムの埋め込みを使用して、次の出力を生成する必要があります。
train: [10 40 50 60], test: [20 30]
train: [20 30 40 60], test: [10 50]
train: [10 20 30 50], test: [40 60]
出力を生成するには、相互検証を実装する必要があります。
どのようにコードセグメントを完成させるべきですか?回答するには、回答領域のダイアログボックスで適切なコードセグメントを選択します。
注:それぞれの正しい選択には1ポイントの価値があります。
正解:
Explanation:
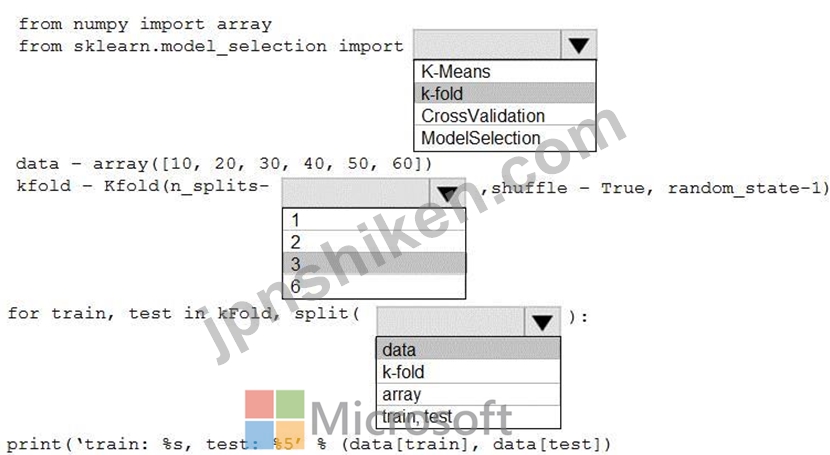
Box 1: k-fold
Box 2: 3
K-Folds cross-validator provides train/test indices to split data in train/test sets. Split dataset into k consecutive folds (without shuffling by default).
The parameter n_splits ( int, default=3) is the number of folds. Must be at least 2.
Box 3: data
Example: Example:
>>>
>>> from sklearn.model_selection import KFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4])
>>> kf = KFold(n_splits=2)
>>> kf.get_n_splits(X)
2
>>> print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]
References:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html

- 質問一覧「196問」
- 質問1 モデルトレーニング要件に適した早期停止基準を実装する必要があ
- 質問2 デザイナーを使用して新しいAzure Machine Learningパイプライン...
- 質問3 Azure Machine Learning Designerを使用して、トレーニングパイ...
- 質問4 モデルのトレーニング要件に従って、順列機能の重要度モジュール
- 質問5 自動機械学習を使用して回帰モデルをトレーニングする予定です。
- 質問6 デザイナーでパイプラインを作成し、自動車価格を予測するモデル
- 質問7 WS1 という名前の Azure Machine Learning ワークスペースがあり...
- 質問8 Azure Machine Learning ワークスペースを作成します。ワークス...
- 質問9 ローカルの機械学習パイプラインのパフォーマンスの問題を解決す
- 質問10 以前は、CSVファイルのフォルダーに基づくtraining-datasetとい...
- 質問11 Azure Machine Learning Studioで実験を作成します-10.000行を含...
- 質問12 機械学習モデルをトレーニングして登録します。モデルを使用して
- 質問13 Azure Machine Learning ワークスペースを作成します。 Azure Ma...
- 質問14 Azure Machine Learning デザイナーを使用して、すべての国の国...
- 質問15 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問16 Azure Machine Learning Designerを使用して、回帰モデルのトレ...
- 質問17 ラベル付き画像のセットを使用するマルチクラス画像分類の深層学
- 質問18 Azure Machine Learning ワークスペースを管理するとします。Azu...
- 質問19 Azure Machine Learning を使用してモデルをトレーニングします...
- 質問20 一連のラベル付き写真を使用するマルチクラス画像分類の深層学習
- 質問21 AzureDatabricksワークスペースとリンクされたAzureMachineLearn...
- 質問22 Azure Machine Learning ワークスペースのノートブックから df ...
- 質問23 バイナリ分類を実行するリカレントニューラルネットワークを構築
- 質問24 workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問25 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問26 workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問27 Azure Machine Learning デザイナーを使用してトレーニング パイ...
- 質問28 Aunt Machine Learning を使用して、機械学習モデルをトレーニン...
- 質問29 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問30 次のコードを使用して、パイプラインのステップを定義します。 a...
- 質問31 Python スクリプトを含む 2 つのステップで、pipeline1 という名...
- 質問32 Azure Machine Learningのハイパードライブ機能を使用して、モデ...
- 質問33 Azure Machine Learningのハイパードライブ機能を使用してモデル...
- 質問34 決定木アルゴリズムを使用して分類モデルをトレーニングします。
- 質問35 画像分類用の深層学習畳み込みニューラル ネットワーク モデルを...
- 質問36 糖尿病の検査を受けた患者の記録を含むデータセットがあります。
- 質問37 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問38 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問39 TensorFlowを使用してディープラーニングモデルを開発しています...
- 質問40 Azure Machine Learning Studioを使用して、機械学習実験を構築...
- 質問41 Azure Machine Learning プロジェクト ファイルを含む既存の Git...
- 質問42 Azure Machine Learning Studioで新しい実験を作成します。多く...
- 質問43 Azure Machine Learningで実験としてスクリプトを実行するには、...
- 質問44 Azure Machine Learning トレーニング実験を実行します。トレー...
- 質問45 Azureを使用して、機械学習、実験を開発しています。 次の画像は...
- 質問46 Azure Machine Learning スタジオを使用して、column1 という名...
- 質問47 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問48 複数の生徒に実践的なワークショップを実施する予定です。ワーク
- 質問49 次の Azure サブスクリプションと Azure Machine Learning サー...
- 質問50 統計分布で非対称性を分析しています。 次の画像には、2つのデー...
- 質問51 ビジネスアプリケーションで使用されるバッチ推論パイプラインを
- 質問52 Azure Machine Learning ワークスペースを管理するとします。 Az...
- 質問53 Python scnpts を含む 2 つのステップを含むパイプライン 1 とい...
- 質問54 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問55 Azure Machine Learning を使用して、Azure ML Python SDK v2 ベ...
- 質問56 Azure Machine Learningデザイナーを使用して実験を構築していま...
- 質問57 広告応答のモデリング戦略を定義する必要があります。 順番に実
- 質問58 マシン チーミング モデルをトレーニングして公開します。 外部...
- 質問59 Azure Machine Learningをサポートするには、Azure Blob Storage...
- 質問60 イベント中のコール数を推定する回帰モデルを構築しています。
- 質問61 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問62 次のように定義された6つのデータポイントを含むPython NumPy配...
- 質問63 woricspace1 という名前の Azure Machine Learning ワークスペー...
- 質問64 ディープラーニング仮想マシン(DLVM)を使用して、コンピューテ...
- 質問65 CPUベースのコンピューティングクラスターとAzureKubernetes Ser...
- 質問66 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問67 Azure Machine Learning ワークスペースがあります。 モデルをト...
- 質問68 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問69 ワークスペース 1 という名前の Azure Machine Learning ワーク...
- 質問70 複数のエポックにわたって畳み込みニューラル ネットワーク モデ...
- 質問71 Azure Machine Learning SDK for Python を使用して、次のステッ...
- 質問72 Azure Machine Learning ワークスペースを管理するとします。 ML...
- 質問73 Azure Machine Learning Studioを使用して実験を作成しています...
- 質問74 スクリプト実行構成を使用してスクリプトを実験として実行する予
- 質問75 組織は、ラベル付きの写真のセットを使用するマルチクラスの画像
- 質問76 自動車の価格データを含む Azure Machine Learning データセット...
- 質問77 同僚が次のコードを使用して、機械学習サービスワークスペースに
- 質問78 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問79 Azure Machine Learning Designer を使用して、次のデータセット...
- 質問80 決定木アルゴリズムを使用しています。次のツリー深度で一般化す
- 質問81 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問82 機械学習実験をトレーニングするためのコンピューティング ター
- 質問83 train.pyという名前のPythonスクリプトを作成し、scriptsという...
- 質問84 分類タスクに取り組んでいます。生徒がサッカーをしたいかどうか
- 質問85 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問86 Azure CLI ml 拡張機能 v2 を使用して Azure Machine Learning ...
- 質問87 トレーニングクラスターと推論クラスターを含むAzure Machine Le...
- 質問88 マルチクラス画像分類深層学習モデルを作成します。 モデルは、
- 質問89 テスト要件に従ってデータを分割する方法を特定する必要がありま
- 質問90 Azure Machine Learning Python SDK を使用して、モデルをトレー...
- 質問91 あなたは猫と犬を識別するために深層学習モデルを交配しています
- 質問92 提供されているトレーニングセットを使用して、バイナリ分類モデ
- 質問93 Azure Machine Learningを使用して、dataset1という名前のデータ...
- 質問94 Azure Machine Learning デザイナーでトレーニング パイプライン...
- 質問95 Azure Machine Learning ワークスペースを管理しています。Azure...
- 質問96 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問97 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問98 オープンソースの深層学習フレームワークCaffe2およびTheanoでDa...
- 質問99 workspace1 という名前の Azure Machine learning ワークスペー...
- 質問100 2,000 行を含むデータセットがあります。 Azure Learning Studio...
- 質問101 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問102 次の Azure サブスクリプションと Azure Machine Learning サー...
- 質問103 Azure MachineLearningワークスペースを使用します。 Webサービ...
- 質問104 バッチ推論パイプラインで使用する予定のモデルを登録します。
- 質問105 workspaces という名前の Azure Machine Learning ワークスペー...
- 質問106 バイナリ分類モデルを作成します。 モデルのパフォーマンスを評
- 質問107 AzureのWindowsおよびLinux用のData Science Virtual Machines(...
- 質問108 Azure Machine Learning ワークスペースがあります。ローカル コ...
- 質問109 あなたのチームは、データエンジニアリングおよびデータサイエン
- 質問110 Azure Machine Learning モデルを作成して、モデル ファイルと軽...
- 質問111 Azure MachineLearningワークスペースを使用します。 次のPython...
- 質問112 Azure Machine Learning ワークスペースがあります。 MLflow モ...
- 質問113 分類タスクを解いています。 k分割交差検定を使用して、限られた...
- 質問114 ノートブックからの Azure ML Python SDK v2 ベースのモデル ト...
- 質問115 Workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問116 モデルをトレーニングして、Azure Machine Learningワークスペー...
- 質問117 Azure Machine Learningで機械学習モデルをトレーニングします。...
- 質問118 Azure Machine Learning Studio を使用して mltabte データ資産...
- 質問119 Azure Machine Learning Studio を使用して、コンピューティング...
- 質問120 Workspace 1 Workspace! という名前の Azure Machine Learning ...
- 質問121 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問122 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問123 Azure MachineLearningワークスペースでモデルを作成して登録し...
- 質問124 Azure Machine Learning ワークスペースは、Python SDK v2 を使...
- 質問125 トレーニングと検証のエラー値に大きな差があるモデルがあります
- 質問126 Python SDK v2 を使用して、workspace1 という名前の Azure Mach...
- 質問127 Azure Machine Learning ワークスペースを作成します。Azure Mac...
- 質問128 デザイナを使用して、分類モデルのトレーニングパイプラインを作
- 質問129 あなたはワイナリーのデータサイエンティストとして雇われていま
- 質問130 完成したバイナリ分類機械学習モデルを評価しています。 評価指
- 質問131 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問132 Azure Machine Learning ワークスペースを管理します。マシンの...
- 質問133 Azure Machine Learning デザイナーを使用して機械学習ソリュー...
- 質問134 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問135 ノートブックで次の Python コードを使用して、モデルを Web サ...
- 質問136 Azure Machine Learning ワークスペースには、real_estate_dat a...
- 質問137 分類モデルをトレーニングしたいデータを含むコンマ区切り値(CS...
- 質問138 機械学習モデルが機密機能全体にわたって不公平な予測を生成しま
- 質問139 トレーニング済みのモデルをAzureMachineLearningワークスペース...
- 質問140 Azure Machine Learning ワークスペースを作成し、MLflow ライブ...
- 質問141 Azure Machine Learning ワークスペースを管理するとします。 特...
- 質問142 Azure Machine Learning Studio を使用してバイナリ分類モデルを...
- 質問143 コンピューティング ターゲットとして Azure Data Science Virtu...
- 質問144 Azure Machine Learning SDK for Python を使用して、Azure Mach...
- 質問145 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問146 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問147 Python SDK v2 を使用して Azure Machine Learning ワークスペー...
- 質問148 Azure ML SDKを使用して実験を実行する準備をしており、コンピュ...
- 質問149 クラスAの100個のサンプルとクラスBの10,000個のサンプルを含む...
- 質問150 Azure Machine Learning ワークスペースを作成します。 ワークス...
- 質問151 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問152 フィーチャエンジニアリングを行って、さらなる分析のためにデー
- 質問153 Azure Machine Learning を使用してハイパー パラメーター チュ...
- 質問154 Azure Machine Learning ワークスペースを管理しています。ワー...
- 質問155 workspace1 という名前の Azure Machine Learning ワークスペー...
- 質問156 Azure Machine Learning ワークスペースを管理します。 Mlftow ...
- 質問157 Azure MachineLearningワークスペースにいくつかの機械学習モデ...
- 質問158 K-meansアルゴリズムを使用してクラスタリングを実行しています...
- 質問159 データセットに対してフィーチャエンジニアリングを実行していま
- 質問160 モデルのトレーニング時に、Azure Machine Learning のハイパー...
- 質問161 Azure Machine Learning ワークスペースがあります。ディープ ラ...
- 質問162 次の数値特徴を含む特徴セットがあります: X、Y、Z。 X、Y、Z 特...
- 質問163 音声認識の深層学習モデルを作成する予定です。 モデルはPython...
- 質問164 パフォーマンスカーブの図に示されているように、広告応答モデル
- 質問165 Azure Machine Learningを使用して、モデルをリアルタイムWebサ...
- 質問166 あなたは、画像分類のための深い畳み込みニューラルネットワーク
- 質問167 フォルダーを参照する csvjolder という名前のファイル データセ...
- 質問168 特徴抽出方法を選択する必要があります。 どの方法を使用する必
- 質問169 Azure Machine Learning ワークスペースを作成し、tram.py とい...
- 質問170 一連のデータサイエンス実験のために、ビルド済みの開発環境を選
- 質問171 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問172 次のコードがあります。このコードは、スクリプトを実行するため
- 質問173 Azure MachineLearningワークスペースを作成します。 DataDriftD...
- 質問174 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問175 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問176 Workspace 1 Workspace! という名前の Azure Machine Learning ...
- 質問177 Azure Machine Learning デザイナーを使用して、Python スクリプ...
- 質問178 Azure Machine Learning Designerを使用して、リアルタイムサー...
- 質問179 機械学習モデルをトレーニングします。 テスト用のリアルタイム
- 質問180 財務チームは、finance-dataという名前のAzure Storage BLOBコン...
- 質問181 生物医学研究会社は、実験的な治療試験に人々を登録することを計
- 質問182 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問183 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問184 C-Support Vector分類を使用して、不均衡なトレーニングデータセ...
- 質問185 Azure Machine Learning ワークスペースがあります。Azure Data ...
- 質問186 Python SDK v2 を使用して、workspace1 という名前の Azure Mach...
- 質問187 Azure Machine Learning ワークスペースを作成します。表形式の...
- 質問188 Azure Machine Learning (ML) モデルがオンライン エンドポイン...
- 質問189 Azure Container Instanceにモデルをデプロイします。 モデルAPI...
- 質問190 ローカル ワークステーションで Azure Machine Learning SDK を...
- 質問191 ワークスペースという名前の Azure Machine Learning ワークスペ...
- 質問192 Azure Machine Learningを使用して機械学習モデルを作成します。...
- 質問193 群衆感情モデルの評価戦略を定義する必要があります。 順番に実
- 質問194 Azure Machine Learning Studioを使用してデータセットを分析し...
- 質問195 Azure Machine Learning Studioを使用して、マルチクラス分類を...
- 質問196 注:この質問は、同じシナリオを提示する一連の質問の一部です。
