- ホーム
- Microsoft
- DP-300J - Administering Relational Databases on Microsoft Azure (DP-300日本語版)
- Microsoft.DP-300J.v2024-01-22.q121
- 質問4
有効的なDP-300J問題集はJPNTest.com提供され、DP-300J試験に合格することに役に立ちます!JPNTest.comは今最新DP-300J試験問題集を提供します。JPNTest.com DP-300J試験問題集はもう更新されました。ここでDP-300J問題集のテストエンジンを手に入れます。
DP-300J問題集最新版のアクセス
「503問、30% ディスカウント、特別な割引コード:JPNshiken」
ADF1という名前のAzureData Factoryインスタンスと、WS1およびWS2という名前の2つのAzure SynapseAnalyticsワークスペースがあります。
ADF1には、次のパイプラインが含まれています。
P1:コピーアクティビティを使用して、WS1の専用SQLプール内のパーティション化されていないテーブルからAzure Data Lake Storage Gen2アカウントにデータをコピーします。P2:コピーアクティビティを使用して、Azure Data Lake StorageGen2アカウント内のテキスト区切りファイルからデータをコピーします。 WS2の専用SQLプール内のパーティション化されていないテーブルへ並列処理とパフォーマンスを最大化するには、P1とP2を構成する必要があります。
各パイプラインのコピーアクティビティに対してどのデータセット設定を構成する必要がありますか?回答するには、回答領域で適切なオプションを選択します。
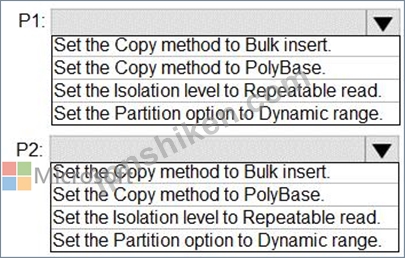
ADF1には、次のパイプラインが含まれています。
P1:コピーアクティビティを使用して、WS1の専用SQLプール内のパーティション化されていないテーブルからAzure Data Lake Storage Gen2アカウントにデータをコピーします。P2:コピーアクティビティを使用して、Azure Data Lake StorageGen2アカウント内のテキスト区切りファイルからデータをコピーします。 WS2の専用SQLプール内のパーティション化されていないテーブルへ並列処理とパフォーマンスを最大化するには、P1とP2を構成する必要があります。
各パイプラインのコピーアクティビティに対してどのデータセット設定を構成する必要がありますか?回答するには、回答領域で適切なオプションを選択します。
正解:

Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-data-warehouse
https://docs.microsoft.com/en-us/azure/data-factory/load-azure-sql-data-warehouse

- 質問一覧「121問」
- 質問1 AzureSQLデータベースがあります。 次の展示に示すように、クエ...
- 質問2 AzureSQLデータベースがあります。データベースには、列ストアイ...
- 質問3 Azure Virtual Machines に SQL Server のインスタンスがありま...
- 質問4 ADF1という名前のAzureData Factoryインスタンスと、WS1およびWS...
- 質問5 Azure サブスクリプションがあります。 Azure SQL データベース...
- 質問6 SQL1 という名前の新しい Azure SQL マネージド インスタンスを...
- 質問7 Windows Server 2019を実行するVM1とVM2という名前の2つのAzure...
- 質問8 オンプレミスのデータセンターにMicrosoftSQL Server2019インス...
- 質問9 Azure サブスクリプションをお持ちです。 書き込みアクセラレー...
- 質問10 Pool1という名前のAzureSynapse Analytics専用SQLプールと、DB1...
- 質問11 Azure SQL データベースを含む Azure サブスクリプションを持っ...
- 質問12 Azure SynapseAnalytics専用のSQLプールで日付ディメンションテ...
- 質問13 5つのデータベースをホストするSQL1という名前のオンプレミスのM...
- 質問14 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問15 Azure SynapseAnalyticsでエンタープライズデータウェアハウスを...
- 質問16 Azure仮想マシンを構築しています。 2つの1-TiB、P30プレミアム...
- 質問17 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問18 Pool1という名前のAzureSynapse Analytics ApacheSparkプールが...
- 質問19 技術的な要件を満たすために、リアルタイム処理のためにどのカウ
- 質問20 DB1という名前のオンプレミスMicrosoftSQL Server2016データベー...
- 質問21 AzureDatabricksで1日1回バッチ処理を実行することを計画してい...
- 質問22 Twitterフィードデータレコードのデータ保持ソリューションを設...
- 質問23 DB1という名前のデータベースを含むAzure仮想マシン上にSQLServe...
- 質問24 オンライン注文のレコードを含むデータセットのスタースキーマを
- 質問25 4つのAzureサブスクリプションがあります。各サブスクリプション...
- 質問26 Table1 という名前のテーブルを含む という名前の Azure SQL デ...
- 質問27 次のAzureDataFactoryパイプラインがあります。 System1からデー...
- 質問28 Web層、アプリケーション層、およびMicrosoft SQLServer層を含む...
- 質問29 次の表に示すリソースを含むAzureサブスクリプションがあります...
- 質問30 DB1 という名前の Azure SQL データベースがあり、Sales という...
- 質問31 Windows Server 2019を実行し、AG1という名前のMicrosoft SQL Se...
- 質問32 Azure Synapseには、dbo.Customersという名前のテーブルを含むSQ...
- 質問33 DB1という名前のデータベースを含むAzure仮想マシン上にSQLServe...
- 質問34 Server1という名前のサーバー上にDatabaseAという名前のAzureSQL...
- 質問35 Orders という名前のテーブルを含む DB1 という名前の Azure SQL...
- 質問36 Azure Virtual Machines 上に VM1 という名前の SQL Server のイ...
- 質問37 DB1という名前のAzureSQLデータベースがあります。DB1には、Col1...
- 質問38 Db1 という名前のデータベースをホストする SQL Server on Azure...
- 質問39 Azure SynapseAnalytics専用のSQLプールでディメンションテーブ...
- 質問40 2つの100GBデータベースをAzureに移動することを計画しています...
- 質問41 Azure Data Lake StorageGen2アカウントへのソースデータの増分...
- 質問42 次のAzureResourceManagerテンプレートがあります。 (Exhibit) ...
- 質問43 MI1という名前のAzureSQLマネージドインスタンスがあります。 MI...
- 質問44 db1 という名前のデータベースがあります。 db1 のログには、次...
- 質問45 SQLMI1 という名前の Azure SQL マネージド インスタンスと Work...
- 質問46 DB1という名前のデータベースをホストするオンプレミスのMicroso...
- 質問47 contoso.comという名前のドメインを使用するAzureサブスクリプシ...
- 質問48 可用性グループの Azure 仮想マシン上に SQL Server があります...
- 質問49 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問50 AzureSQLデータベースがあります。 次の展示に示すように、パフ...
- 質問51 Azure サブスクリプションがあります。 Azure Resource Manager ...
- 質問52 SalesSQLDb1のフェイルオーバー後に、SalesSQLDb1App1がデータベ...
- 質問53 ファイルがAzureData Lake Storage Gen2コンテナーに到着したと...
- 質問54 DB1という名前のデータベースを含むAzure仮想マシン上にSQLServe...
- 質問55 次のデータベースレベルおよびインスタンスレベルの機能を使用す
- 質問56 Pool1という名前のApacheSparkプールを含むWS1という名前のAzure...
- 質問57 DB1という名前のAzureSQLデータベースがあります。 DB1の自動チ...
- 質問58 SQLMI1という名前のAzureSQLDatabaseマネージドインスタンスがあ...
- 質問59 標準料金階層にworkspace1という名前のAzureDatabricksワークス...
- 質問60 さまざまな量のデータを取り込むストリーミングデータソリューシ
- 質問61 SalesSQLDb1の監視を実装する必要があります。ソリューションは...
- 質問62 sqldb1 という名前の Azure SQL データベースがあります。 クエ...
- 質問63 DB1という名前のAzureSQLデータベースがあります。 タイプCHAR(...
- 質問64 db1 という名前のデータベースをホストするオンプレミスの Micro...
- 質問65 Azure SQL データベースがあります。 次の要件を満たす災害復旧...
- 質問66 2つの100GBデータベースをAzureに移動することを計画しています...
- 質問67 AzureSQLデータベースがあります。 次のPowerShellスクリプトを...
- 質問68 VNet1という名前の仮想ネットワーク上にVM1という名前のAzure仮...
- 質問69 オンプレミスのデータセンターに Microsoft SQL Server 2019 イ...
- 質問70 AzureSQLマネージドインスタンスがあります。 Transact-SQLを使...
- 質問71 次のリソースを含む Azure サブスクリプションがあります。 * 10...
- 質問72 オンプレミス ネットワークには、DB 1 という名前の 60 TB のデ...
- 質問73 VM1 という名前の SQL Server on Azure Virtual Machines インス...
- 質問74 SQL1 と SQL2 という名前の 2 つのオンプレミス Microsoft SQL S...
- 質問75 トランザクションデータの分析ストレージソリューションを設計す
- 質問76 VNet1という名前の仮想ネットワーク上にVM1という名前のAzure仮...
- 質問77 SERVER1データベースの移行を計画しています。ソリューションは...
- 質問78 次の表に示すリソースを含む Azure サブスクリプションがありま...
- 質問79 オンプレミスの Microsoft SQL Server データベースのディザスタ...
- 質問80 sqldb1という名前のAzureSQLデータベースがあります。 sqldb1の...
- 質問81 次の表に示すリソースを含むAzureサブスクリプションがあります...
- 質問82 VNet1という名前の仮想ネットワーク上にVM1という名前のAzure仮...
- 質問83 Azure仮想マシン上にSQLServerがあります。 次の展示に示されて...
- 質問84 df1という名前のAzureData Factoryバージョン2(V2)データファ...
- 質問85 Windows Server 2022 を実行し、SQL1 という名前の Microsoft SQ...
- 質問86 AzureSQLデータベースを使用するソリューションを計画しています...
- 質問87 10 の Azure リージョンにまたがる 100 の Azure SQL マネージド...
- 質問88 オンプレミスのMicrosoftSQLServerデータベースをAzureSQLDataba...
- 質問89 Azure Data Lake StorageGen2コンテナがあります。 データはコン...
- 質問90 オンプレミス ネットワークには、db1 という名前のデータベース...
- 質問91 index1 という名前の非クラスター化インデックスを含む DBI とい...
- 質問92 db1 という名前のデータベースをホストする SQL1 という名前のオ...
- 質問93 ゲームデータを取得するためのAzureStreamAnalyticsジョブを構築...
- 質問94 DB1 という名前の Azure SQL データベースがあります。 User 1 ...
- 質問95 AzSQL1という名前のAzureSQLサーバー上にDB1という名前の新しいA...
- 質問96 Azure Data Lake Storage Gen2を使用するアプリケーションを開発...
- 質問97 AzureSQLデータベースを含むAzureサブスクリプションがあります...
- 質問98 vCore購入モデルを使用してプロビジョニングされた20のAzureSQL...
- 質問99 DB1 という名前の Azure SQL データベースがあります。DB1 には...
- 質問100 DB1 という名前の Microsoft SQL Server 2019 データベースと、S...
- 質問101 SQLDb1 という名前の Azure SQL データベースを含む Azure サブ...
- 質問102 DB1 という名前の Azure SQL データベースがあります。 DB1 を暗...
- 質問103 10個のパイプラインを含むAzureDataFactoryがあります。 各パイ...
- 質問104 Azure サブスクリプションがあります。 Microsoft SQL Server イ...
- 質問105 DB1という名前のAzureSQLデータベースがあります。 Azureポータ...
- 質問106 ResourceGroup1という名前のリソースグループ内の同じAzureSQLデ...
- 質問107 Db1という名前のデータベースを含むAzure仮想マシン上にSQLServe...
- 質問108 R を主要言語としてサポートするが、Scala と SQL もサポートす...
- 質問109 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問110 SQLMi1という名前のAzureSQLマネージドインスタンスとBackupdbと...
- 質問111 SQLMI1 と SQLMI2 という名前の 2 つの Azure SQL マネージド イ...
- 質問112 Azure StreamAnalyticsジョブを監視しています。 バックログ入力...
- 質問113 同じ論理サーバー上に5つのAzureSQLデータベースインスタンスを...
- 質問114 Databasebackups という名前のストレージ アカウントを含む Azur...
- 質問115 Azure サブスクリプションをお持ちです。 次の要件を満たす Azur...
- 質問116 DB1 という名前の 2 TB Microsoft SQL Server 2019 データベース...
- 質問117 次の展示に示すように、Azure DataFactoryインスタンスのバージ...
- 質問118 AzureDatabricksで構造化ストリーミングソリューションを構築す...
- 質問119 Azure Synapse Analyticsで、Customersという名前のテーブルを含...
- 質問120 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問121 factSalesという名前のテーブルを含むAzureSQLデータベースがあ...
