- ホーム
- Microsoft
- DP-203J - Data Engineering on Microsoft Azure (DP-203日本語版)
- Microsoft.DP-203J.v2025-03-07.q151
- 質問28
有効的なDP-203J問題集はJPNTest.com提供され、DP-203J試験に合格することに役に立ちます!JPNTest.comは今最新DP-203J試験問題集を提供します。JPNTest.com DP-203J試験問題集はもう更新されました。ここでDP-203J問題集のテストエンジンを手に入れます。
DP-203J問題集最新版のアクセス
「365問、30% ディスカウント、特別な割引コード:JPNshiken」
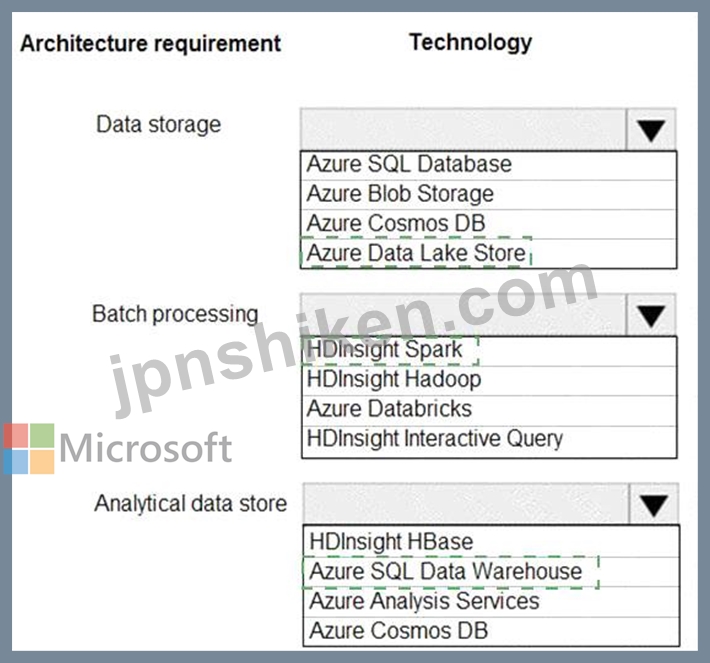
あなたは、Microsoft Azure で Lambda アーキテクチャを使用してソリューションを開発しています。
テスト レイヤーのデータは、次の要件を満たす必要があります。
データストレージ:
* リポジトリ (またはさまざまな形式の大量の大きなファイル) として機能します。
* ビッグ データ分析ワークロード用に最適化されたストレージを実装します。
* データが階層構造を使用して編成できることを確認します。
バッチ処理:
* インメモリ計算処理にはマネージド ソリューションを使用します。
* Scala、Python、および R プログラミング言語をネイティブにサポートします。
* クラスターのサイズを変更して自動的に終了する機能を提供します。
分析データ ストア:
* 並列処理をサポートします。
* カラムナストレージを使用します。
* SQL ベースの言語をサポートします。
Lambda アーキテクチャを構築するには、正しいテクノロジーを特定する必要があります。
どのテクノロジを使用する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。注: 正しい選択ごとに 1 ポイントの価値があります。

テスト レイヤーのデータは、次の要件を満たす必要があります。
データストレージ:
* リポジトリ (またはさまざまな形式の大量の大きなファイル) として機能します。
* ビッグ データ分析ワークロード用に最適化されたストレージを実装します。
* データが階層構造を使用して編成できることを確認します。
バッチ処理:
* インメモリ計算処理にはマネージド ソリューションを使用します。
* Scala、Python、および R プログラミング言語をネイティブにサポートします。
* クラスターのサイズを変更して自動的に終了する機能を提供します。
分析データ ストア:
* 並列処理をサポートします。
* カラムナストレージを使用します。
* SQL ベースの言語をサポートします。
Lambda アーキテクチャを構築するには、正しいテクノロジーを特定する必要があります。
どのテクノロジを使用する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。注: 正しい選択ごとに 1 ポイントの価値があります。
正解:
Explanation:
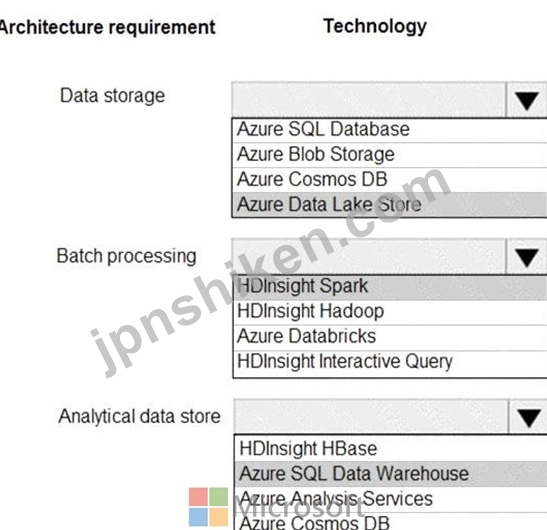
Data storage: Azure Data Lake Store
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on your computer is organized. With the hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Batch processing: HD Insight Spark
Aparch Spark is an open-source, parallel-processing framework that supports in-memory processing to boost the performance of big-data analysis applications.
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP, MapReduce.
Languages: R, Python, Java, Scala, SQL
Analytic data store: SQL Data Warehouse
SQL Data Warehouse is a cloud-based Enterprise Data Warehouse (EDW) that uses Massively Parallel Processing (MPP).
SQL Data Warehouse stores data into relational tables with columnar storage.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-overview-what-is

- 質問一覧「151問」
- 質問1 Microsoft Purview アカウントを持っている。次の図は、CSV ファ...
- 質問2 SQL1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問3 Azure データ ファクトリがあります。 パイプライン実行データが...
- 質問4 Folder と Folder2 という名前の 2 つのフォルダーを含む Azure ...
- 質問5 Azure Synapse Analytics ワークスペースと Used という名前のユ...
- 質問6 ServicePrincipal1という名前のサービスプリンシパルを含むAzure...
- 質問7 新しいファイルが Azure Data Lake Storage Gen2 コンテナーに到...
- 質問8 Azure Synapse Analytics ワークスペースがあります。 Azure Syn...
- 質問9 ステージングゾーンを含むAzureData LakeStorageアカウントがあ...
- 質問10 100 TB のデータを含む Azure Data Lake Storage Gen2 コンテナ...
- 質問11 storage1という名前のAzureBlobStorageアカウントとPool1という...
- 質問12 WS1 という名前の Azure Synapse Analytics ワークスペースがあ...
- 質問13 Webサイト分析システムから、ダウンロード、リンククリック、フ...
- 質問14 DB1 と DB2 という名前の 2 つの Azure SQL データベースがあり...
- 質問15 AzureDatabricksワークスペースを含むAzureサブスクリプションが...
- 質問16 Apache Kafkaで発生し、Azure Data Lake StorageGen2に出力され...
- 質問17 企業全体の Azure Data Lake Storage Gen2 アカウントを持ってい...
- 質問18 次の図に示す Azure Synapse Analytics パイプラインがあります...
- 質問19 databricks1 という名前の Azure Databricks ワークスペースと s...
- 質問20 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問21 Azure Event Hubs からのほぼリアルタイムのデータで独自のカス...
- 質問22 Azure Databricks リソースがあります。 Databricks リソースの...
- 質問23 AzureSynapseにSQLプールがあります。 AzureBlobストレージから...
- 質問24 account1 という名前の Azure Data Lake Storage Gen2 アカウン...
- 質問25 Azure Data Lake Storage Gen2 アカウントのファイルのフォルダ...
- 質問26 ws1 という名前の Azure Synapse Analytics ワークスペースと Co...
- 質問27 料金所を通過する車両からのストリーミングデータを処理していま
- 質問28 あなたは、Microsoft Azure で Lambda アーキテクチャを使用して...
- 質問29 ADM という名前の Azure データ ファクトリがあり、これには Pip...
- 質問30 pool1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問31 AzureIoTハブからデータをストリーミングするための異常検出ソリ...
- 質問32 Azure Data Lake Storage Gen 2 アカウントを使用して、料金所の...
- 質問33 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問34 Azure Databricks を使用するストリーミング データ ソリューシ...
- 質問35 Twitterフィードデータレコードのデータ保持ソリューションを設...
- 質問36 container1 という名前のコンテナーを含む Azure Data Lake Stor...
- 質問37 Azure データ ファクトリを含む Azure サブスクリプションがあり...
- 質問38 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問39 次のAzureDataFactoryパイプラインがあります *システム1からデ...
- 質問40 Trigger1 というタンブリング ウィンドウ トリガーによって呼び...
- 質問41 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールを...
- 質問42 Azure Synapse AnalyticsサーバーレスSQLプールを使用して、Azur...
- 質問43 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問44 ADF1 という名前の Azure データ ファクトリを含む Azure サブス...
- 質問45 製品カタログファイルから参照データをクエリするAzureStreamAna...
- 質問46 次の要件を満たす Azure Synapse Analytics 専用の SQL プールを...
- 質問47 Azureのメトリックを使用して、Azure StreamAnalyticsジョブを監...
- 質問48 Azure SynapseAnalytics専用のSQLプールにデータウェアハウスを...
- 質問49 Azure Synapse サーバーレス SQL プールがあります。 OPENROWSET...
- 質問50 毎日200,000個の新しいファイルを生成するAzureStorageアカウン...
- 質問51 Azure Data Factory からファイルを出力する必要があります。 出...
- 質問52 Workspaces という名前の Azure Synapse Analytics ワークスペー...
- 質問53 デバイスが指定された場所から200メートル以上離れたときにユー...
- 質問54 3 つのパイプラインと、Trigger 1、Trigger2、Tiigger3 という名...
- 質問55 JSON 形式のデータを取り込む Apache Spark ジョブを Azure Data...
- 質問56 Azure Synapse Analytics専用のSQLプールで、製品カテゴリデータ...
- 質問57 Job1 という名前の Azure Stream Analytics ジョブがあります。 ...
- 質問58 Azure DatabricksでPySparkを使用して、次のJSON入力を解析しま...
- 質問59 Azure Data Lake StorageGen2の何千ものCSVファイルにデータが保...
- 質問60 次の表に示すリソースを含む Azure サブスクリプションがありま...
- 質問61 会社の人材(MR)部門向けのデータマートを設計しています。デー...
- 質問62 Azure DevOps に Repo1 という名前のリポジトリを含むプロジェク...
- 質問63 pool1という名前のAzureSynapseAnalytics専用SQLプールがありま...
- 質問64 ADF1 という名前の Azure データ ファクトリを含む Azure サブス...
- 質問65 Azure Data Lake Gen2 ストレージ アカウントを実装する予定です...
- 質問66 温度という名前の Apache Spark DataFrame があります。データの...
- 質問67 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問68 顧客用のJSONファイルを含むAzureData Lake StorageGen2アカウン...
- 質問69 ユーザー定義のローカル プロセスを実行する Azure Databricks ...
- 質問70 Pool1という名前のAzureSynapse Analytics ApacheSparkプールが...
- 質問71 Azure Synapse Analytics で、Customers という名前のテーブルを...
- 質問72 Azure Data Factory には、太平洋時間でスケジュールされたスケ...
- 質問73 Tablet という名前の Delta Lake ディメンション テーブルを含む...
- 質問74 Group1 という名前のセキュリティ グループを含む Azure Active ...
- 質問75 mytestdb という名前の Apache Spark データベースを含む MyWork...
- 質問76 同時実行性が 1 に設定されている pipeline1 という名前の Azure...
- 質問77 Df1 という名前の Azure Data Factory バージョン 2 (V2) リソー...
- 質問78 Azure SynapseAnalytics専用のSQLプールで金融トランザクション...
- 質問79 Contacts という名前のテーブルを含む Azure Synapse Analystics...
- 質問80 Azure Synapse Analyticsで、スタースキーマにWebサイトのトラフ...
- 質問81 Azure Synapse Analytics 専用 SQL プールにスター スキーマを実...
- 質問82 複数の会社をサポートするAzureSynapseAnalytics専用SQLプールの...
- 質問83 次の表に示すリソースを含む Azure サブスクリプションがありま...
- 質問84 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールと...
- 質問85 次の展示に示すアクティビティを持つAzureDataFactoryパイプライ...
- 質問86 Azure SynapseAnalyticsワークスペースを設計しています。 保存...
- 質問87 ストレージ アカウントを含む Azure サブスクリプションがありま...
- 質問88 Azure Synapse Analytics 専用の SQL プールでデータ ウェアハウ...
- 質問89 ハイブリッドAzureActive Directory(Azure AD)テナントにリン...
- 質問90 storage1 という名前の Azure Data Lake Storage Gen2 アカウン...
- 質問91 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールを...
- 質問92 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問93 Azure Stream Analytics クエリがあります。クエリは、clusterID...
- 質問94 Pool1 という Azure Synapse Analytics サーバーレス SQL プール...
- 質問95 次の表に示すように、ログを保存するaccount1という名前のAzure ...
- 質問96 Sales.Orders という名前のテーブルを含む Azure Synapse Analyt...
- 質問97 重要な顧客の連絡先情報を保護するために何を使用することをお勧
- 質問98 ある企業は、製造機械を監視するために IoT デバイスを購入しま...
- 質問99 AzureDatabricksワークスペースとstorageという名前のAzureDataL...
- 質問100 製品販売トランザクションのパーティションを設計する必要があり
- 質問101 Azure Stream Analytics を使用して、ストリーミング ソーシャル...
- 質問102 分析ワークロードで使用するために raw JSON ファイルを変換する...
- 質問103 次の表に示す Azure Synapse Analytics ワークスペースを含む Az...
- 質問104 Pool1という名前のApacheSparkプールを含むWS1という名前のAzure...
- 質問105 Azure IoT Hub から入力データを受け取り、結果を Azure Blob St...
- 質問106 Azure Cosmos DB 分析ストアと WS 1 という名前の Azure Synapse...
- 質問107 次の展示に示すように、Azure DataFactoryインスタンスのバージ...
- 質問108 CSV ファイルを含む Azure Data Lake Storage アカウントがあり...
- 質問109 次の Azure Stream Analytics クエリがあります。 (Exhibit) 次...
- 質問110 Microsoft Visual Studio の Stream Analytics プロジェクト ソ...
- 質問111 データ ウェアハウスのディメンション テーブルを設計しています...
- 質問112 Azure Data Lake Storage Gen2を使用して、データサイエンティス...
- 質問113 顧客用の JSON ファイルを含む Azure Data Lake Storage Gen2 ア...
- 質問114 CSV ファイルを格納する Azure Data Lake Storage Gen2 コンテナ...
- 質問115 Azure Cosmos DB データベースを含む Azure サブスクリプション...
- 質問116 次の展示に示すアクティビティを備えたものです。 (Exhibit) ド...
- 質問117 ある会社は、侵入検知データを分析するために Apache Spark 分析...
- 質問118 Table1 という名前のテーブルを含む、SA1 という名前の Azure Sy...
- 質問119 販売トランザクション データを格納するための Azure Synapse An...
- 質問120 Pipeline1! という名前の Azure Data Factory パイプラインがあ...
- 質問121 Azure Synapse Analytics 専用の SQL プールを作成する予定です...
- 質問122 Azure Data Lake Storage Gen2を使用するアプリケーションを開発...
- 質問123 Azure Synapse Analytics 専用 SQL プール内のファクト テーブル...
- 質問124 Azure Synapse Analytics 専用 SQL プールのテーブルにデータを...
- 質問125 Standard 価格レベルに、workspace1 という名前の Azure Databri...
- 質問126 リアルタイム データ処理ソリューションの高可用性を向上させる
- 質問127 CSVファイルからデータを取り込み、指定されたタイプのデータに...
- 質問128 データ ウェアハウスがあります。 ProductName、ProductColor、...
- 質問129 Azure Synapse Analytics 専用の SQL プールで、サプライヤー デ...
- 質問130 あなたは、企業向けのデータ エンジニアリング ソリューションを...
- 質問131 eコマーストランザクションの不正を検出するためのワークロード
- 質問132 Azure Stream Analytics を使用して、Azure Event Hubs から Twi...
- 質問133 Azure Synapse Analytics 専用の SQL プールがあります。 過去 3...
- 質問134 あなたは、Dataflow1 という名前のマッピング データ フローを含...
- 質問135 Azure SynapseAnalyticsにエンタープライズデータウェアハウスが...
- 質問136 Azure Data Lake Storage Gen2 アカウントのフォルダー構造を設...
- 質問137 あなたは、ペタバイト規模の医用画像データを保存するアプリケー
- 質問138 Azure Event Hubs からのほぼリアルタイムのデータに対して、独...
- 質問139 Microsoft Entra テナントがあります。 テナントには、storage ...
- 質問140 大規模なファクト テーブルを含む Azure Synapse Analytics 専用...
- 質問141 Microsoft Purview アカウントを含む Azure サブスクリプション...
- 質問142 Azure Synapse Analytics 専用の SQL プールがあります。 クラス...
- 質問143 Azure Data Factory を使用して、Azure Synapse Analytics サー...
- 質問144 Azureサブスクリプションがあります。 ステージングテーブルを含...
- 質問145 R を主要言語としてサポートするが、Scale と SOL もサポートす...
- 質問146 Pipeline1とPipeline2という名前の2つのパイプラインを含むAzure...
- 質問147 SQLPool1 という名前の Azure Synapse Analytics 専用 SQL プー...
- 質問148 Azure Stream Analyticsを使用して、Azure Event HubsからTwitte...
- 質問149 Azure Synapse Analytics 専用の SQL プールにテーブルがありま...
- 質問150 workspace1 という名前の Azure Synapse Analytics ワークスペー...
- 質問151 SQL サーバーから Azure Data Lake Storage に日次インベントリ ...
