- ホーム
- Microsoft
- DP-203J - Data Engineering on Microsoft Azure (DP-203日本語版)
- Microsoft.DP-203J.v2025-02-04.q160
- 質問85
有効的なDP-203J問題集はJPNTest.com提供され、DP-203J試験に合格することに役に立ちます!JPNTest.comは今最新DP-203J試験問題集を提供します。JPNTest.com DP-203J試験問題集はもう更新されました。ここでDP-203J問題集のテストエンジンを手に入れます。
DP-203J問題集最新版のアクセス
「365問、30% ディスカウント、特別な割引コード:JPNshiken」
7つの主要な地理的地域に分散された2500万台のデバイスからのテレメトリデータ用のAzureData Lake StorageGen2構造を設計しています。毎分、デバイスはメトリックのJSONペイロードをAzure EventHubsに送信します。
データのフォルダ構造を推奨する必要があります
NS。ソリューションは、次の要件を満たしている必要があります。
各地域のデータエンジニアは、それぞれの地域のデータに対してのみ独自のパイプラインを構築できる必要があります。
Azure Synapse AnalyticsサーバーレスSQLプールに含めるには、データを少なくとも15分ごとに1回処理する必要があります。
構造を完成させることをどのように推奨しますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。
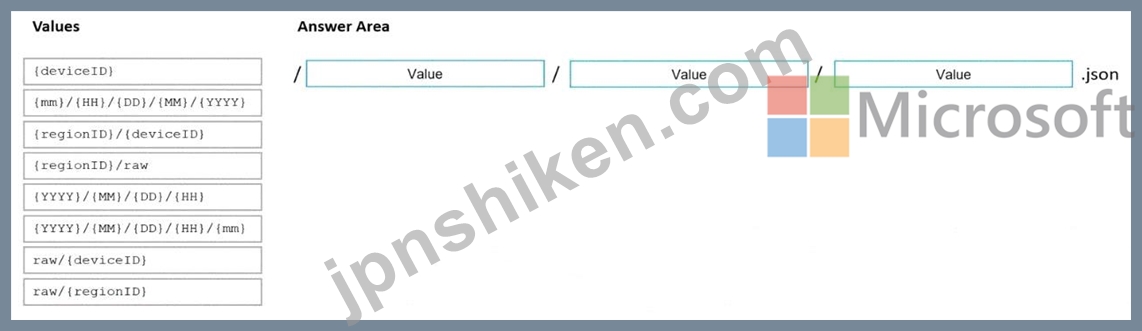
データのフォルダ構造を推奨する必要があります
NS。ソリューションは、次の要件を満たしている必要があります。
各地域のデータエンジニアは、それぞれの地域のデータに対してのみ独自のパイプラインを構築できる必要があります。
Azure Synapse AnalyticsサーバーレスSQLプールに含めるには、データを少なくとも15分ごとに1回処理する必要があります。
構造を完成させることをどのように推奨しますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。
正解:

Explanation:
Box 1: {YYYY}/{MM}/{DD}/{HH}
Date Format [optional]: if the date token is used in the prefix path, you can select the date format in which your files are organized. Example: YYYY/MM/DD Time Format [optional]: if the time token is used in the prefix path, specify the time format in which your files are organized. Currently the only supported value is HH.
Box 2: {regionID}/raw
Data engineers from each region must be able to build their own pipelines for the data of their respective region only.
Box 3: {deviceID}
Reference:
https://github.com/paolosalvatori/StreamAnalyticsAzureDataLakeStore/blob/master/README.md

- 質問一覧「160問」
- 質問1 Azure Synapse Analytics で、Customers という名前のテーブルを...
- 質問2 Azure Blob Storage アカウントに保存されている Parquet ファイ...
- 質問3 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問4 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問5 AzureSynapseにSQLプールがあります。 AzureBlobストレージから...
- 質問6 次の展示に示すアクティビティを持つAzureDataFactoryパイプライ...
- 質問7 Azure Synapse Analytics 専用 SQL プールを含む Azure サブスク...
- 質問8 Azure SynapseAnalytics専用のSQLプールを設計しています。 次の...
- 質問9 pool1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問10 企業全体の Azure Data Lake Storage Gen2 アカウントを持ってい...
- 質問11 ws1 という名前の Azure Synapse Analytics ワークスペースと Co...
- 質問12 顧客用の JSON ファイルを含む Azure Data Lake Storage Gen2 ア...
- 質問13 次の図に示すように、Git リポジトリ設定を持つ Azure データ フ...
- 質問14 ジオゾーン冗長ストレージ(GZRS)を導入する高可用性Azure Data...
- 質問15 Azure Synapse Analytics ワークスペースがあります。 Azure Syn...
- 質問16 Azure データ ファクトリがあります。 過去 60 日間のパイプライ...
- 質問17 Azure Synapse Analytics サーバーレス SQL プールにデータベー...
- 質問18 Azure Databricks を使用するストリーミング データ ソリューシ...
- 質問19 Azure Synapse Analytics 専用の SQL プールがあります。 過去 3...
- 質問20 workspace1 という名前の Azure Synapse Analytics ワークスペー...
- 質問21 Azure Synapse Analytics 専用 SQL プールのテーブルにデータを...
- 質問22 Azure Synapseに、dbo.Customersという名前のテーブルを含むSQL...
- 質問23 Azure Data Lake Storage Gen2 コンテナーにファイルを保存しま...
- 質問24 オンプレミスのデータ ソースと Azure Synapse Analytics を統合...
- 質問25 Azure SynapseAnalyticsワークスペースを設計しています。 保存...
- 質問26 Azure Event Hubからのストリーミングデータを処理し、そのデー...
- 質問27 Azure Data Factory を使用して、Azure Synapse Analytics サー...
- 質問28 Microsoft Visual Studio の Stream Analytics プロジェクト ソ...
- 質問29 MP1 という名前の Microsoft Purview アカウント、DF1 という名...
- 質問30 次の要件を満たす Azure Synapse Analytics 専用の SQL プールを...
- 質問31 Azure Data Lake Storage Gen2 を使用します。 データがディスク...
- 質問32 Azureサブスクリプションがあります。 ステージングテーブルを含...
- 質問33 AzureSynapseAnalyticsで1GB未満のディメンションテーブルを作成...
- 質問34 Azure Stream Analytics のウィンドウ関数を実装しています。 要...
- 質問35 Azure Data Lake Storage Gen2を使用して、データサイエンティス...
- 質問36 ジオゾーン冗長ストレージ(GZRS)を含む高可用性Azure Data Lak...
- 質問37 Azure Synapse Analytics 専用の SQL プールがあります。 プール...
- 質問38 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問39 Pool1 という Azure Synapse Analytics サーバーレス SQL プール...
- 質問40 storage1 という名前の Azure Data Lake Storage Gen2 アカウン...
- 質問41 あなたは、500 台の車両の監視ソリューションを設計しています。...
- 質問42 FlightとWeatherという名前の2つのファクトテーブルがあります。...
- 質問43 次のリソースを含むAzureサブスクリプションがあります。 Group1...
- 質問44 Azure Data Lake Storage Gen2 コンテナーのフォルダー構造を設...
- 質問45 Azure Event Hubs からのほぼリアルタイムのデータで独自のカス...
- 質問46 Azureサブスクリプションがあります。 Azure Data Lake Storage ...
- 質問47 R を主要言語としてサポートするが、Scale と SOL もサポートす...
- 質問48 Pipeline1 という名前の Azure Data Factory データ パイプライ...
- 質問49 Pool1という名前のApacheSparkプールを含むWS1という名前のAzure...
- 質問50 Folder と Folder2 という名前の 2 つのフォルダーを含む Azure ...
- 質問51 Azure Synapse Analytics 専用の SQL プールで FactPurchase と...
- 質問52 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問53 3 つのパイプラインと、Trigger 1、Trigger2、Tiigger3 という名...
- 質問54 JSON 形式のデータを取り込む Apache Spark ジョブを Azure Data...
- 質問55 Azure SynapseAnalytics専用のSQLプールにデータウェアハウスを...
- 質問56 製品販売トランザクションのデータ ストレージ構造を設計する必
- 質問57 Storage1とStorage2という名前の2つのAzureStorageアカウントが...
- 質問58 DB1 という名前の Azure SQL データベースと、pipeline という名...
- 質問59 Azure Synapse Analytics 専用の SQL プールがあります。 データ...
- 質問60 Azure Data Lake Storage Gen2 アカウントのファイルのフォルダ...
- 質問61 ある企業は、製造機械を監視するために IoT デバイスを購入しま...
- 質問62 Azure Stream Analytics にストリーミングするソリューションを...
- 質問63 Azure SynapseAnalyticsにエンタープライズデータウェアハウスが...
- 質問64 マッピングデータフローを含むAzureDataFactoryパイプラインを作...
- 質問65 Azure データ要素があり、次のブランチを含む Git リポジトリに...
- 質問66 ADFdev と ADFprod という 2 つの Azure Data Factory インスタ...
- 質問67 CSVファイルからデータを取り込み、指定されたタイプのデータに...
- 質問68 ADF1 という名前の Azure データ ファクトリを含む Azure サブス...
- 質問69 フォルダーを含む Azure Blob ストレージ アカウントがあります...
- 質問70 ADFdev と ADFprod という名前の 2 つの Azure Data Factory イ...
- 質問71 Microsoft Azure SQL データ ウェアハウスの実装の監視を構成し...
- 質問72 3番目の正規形スキーマを使用するMicrosoftSQLServerデータベー...
- 質問73 Azure StreamAnalyticsジョブを監視しています。 バックログ入力...
- 質問74 次の Azure Stream Analytics クエリがあります。 (Exhibit) 次...
- 質問75 Azure Synapse Analytics 専用の SQL プールにテーブルがありま...
- 質問76 Pipeline1! という名前の Azure Data Factory パイプラインがあ...
- 質問77 Azure IoT ハブからのデータを処理し、複雑な変換を実行する C# ...
- 質問78 Pool1という名前のAzureSynapse Analytics専用SQLプールと、DB1...
- 質問79 Azure Databricks 上の Delta Lake のテーブルを使用する 2 つの...
- 質問80 ストレージ アカウントを含む Azure サブスクリプションがありま...
- 質問81 Azure SynapseAnalytics専用のSQLプールで日付ディメンションテ...
- 質問82 仮想ネットワーク サービス エンドポイントが構成されている Azu...
- 質問83 次のコードセグメントは、AzureDatabricksクラスターを作成する...
- 質問84 Microsoft Purview アカウントに接続する Azure データ ファクト...
- 質問85 7つの主要な地理的地域に分散された2500万台のデバイスからのテ...
- 質問86 Azure Stream Analytics を使用して、Azure Event Hubs から Twi...
- 質問87 Azure Synapse Analyticsに、Server1という名前のサーバー上のDW...
- 質問88 Azure IoT Hub から入力データを受け取り、結果を Azure Blob St...
- 質問89 AzureDatabricksで構造化ストリーミングソリューションを構築す...
- 質問90 ユーザー定義のローカル プロセスを実行する Azure Databricks ...
- 質問91 Table1 という名前のテーブルを含む Azure Synapse Analytics 専...
- 質問92 Azure Synapse Analytics で Apache Spark プールを使用して、Az...
- 質問93 監視と管理アプリを使用して Azure データ ファクトリを監視する...
- 質問94 製品カタログファイルから参照データをクエリするAzureStreamAna...
- 質問95 次の Azure Stream Analytics クエリがあります。 (Exhibit) 次...
- 質問96 AzureSynapseにSQLプールがあります。 一部のクエリが失敗するか...
- 質問97 Azure Synapse Analytics 専用 SQL プールでディメンション テー...
- 質問98 会社の次の 3 つの部門のデータを処理するための Azure Data Fac...
- 質問99 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問100 ADF1 という名前の Azure データ ファクトリがあります。 現在、...
- 質問101 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問102 Webサイト分析システムから、ダウンロード、リンククリック、フ...
- 質問103 Azure Data Lake Storage Gen 2 アカウントを使用して、料金所の...
- 質問104 次の図に示すように、Azure Synapse ワークスペースの Azure Dat...
- 質問105 重要な顧客の連絡先情報を保護するために何を使用することをお勧
- 質問106 Azure Event Hubsから受信したデータを処理し、Azure Data Lake ...
- 質問107 新しいファイルが Azure Data Lake Storage Gen2 コンテナーに到...
- 質問108 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問109 Microsoft Purview アカウントを持っている。次の図は、CSV ファ...
- 質問110 ファイルがAzureData Lake Storage Gen2コンテナーに到着したと...
- 質問111 Azure Active Directory(Azure AD)統合を使用して、Azure Data...
- 質問112 Azureデータファクトリがあります。 最後の180フレイからのパイ...
- 質問113 WS1 という名前の Azure Synapse Analytics ワークスペースがあ...
- 質問114 16 個のパーティションを持つ、retailhub という名前の Azure イ...
- 質問115 Pcol1 という名前の Azure Synapse Analytics 専用 SQL プールが...
- 質問116 Azure Synapse Analytics 専用の SQL プールがあります。 PDW_SH...
- 質問117 Azure Synapse Analytics 専用の SQL プールにパーティション分...
- 質問118 Table1 という名前のテーブルを含む Azure Synapse Analytics 専...
- 質問119 Poo 11 という名前の Azure Synapse Analytics 専用 SQL プール...
- 質問120 Azure Synapse Analytics サーバーレス SQL プール、Azure Synap...
- 質問121 DW1という名前のAzureSynapseAnalyticsのエンタープライズデータ...
- 質問122 次の図に示されている Azure Data Factory パイプラインがありま...
- 質問123 Azure Stream Analyticsを使用して、Azure Event HubsからTwitte...
- 質問124 Azure SynapseAnalytics専用のSQLプールでインベントリ更新テー...
- 質問125 次の図に示すように、Azure Synapse Analytics のデータ ウェア...
- 質問126 仮想ネットワークによって保護されているadls2という名前のAzure...
- 質問127 Microsoft Entra テナントがあります。 テナントには、fs1 と fs...
- 質問128 ある会社は、侵入検知データを分析するために Apache Spark 分析...
- 質問129 Pool1という名前のAzureSynapse Analytics専用SQLプールと、DB1...
- 質問130 デバイスからのイベントデータを処理するためのAzureStreamAnaly...
- 質問131 次の図に示すように、ソース管理に Git リポジトリを使用するよ...
- 質問132 ADM という名前の Azure データ ファクトリがあります。 現在、...
- 質問133 会社はAzureStreamAnalyticsを使用してデバイスを監視しています...
- 質問134 Azure DevOps に Repo1 という名前のリポジトリを含むプロジェク...
- 質問135 Azure Synapse Analytics 専用の SQL プールがあります。 クラス...
- 質問136 Azure Databricks クラスターを作成し、インストールする追加の...
- 質問137 ある企業は Azure Data Lake Storage Gen2 サービスを使用してい...
- 質問138 次の種類のアクティビティが混在する Azure Data Factory パイプ...
- 質問139 ユーザーが Web ページの機能を操作するために費やす時間を特定...
- 質問140 ADF1という名前のAzureData Factoryインスタンスと、WS1およびWS...
- 質問141 注: この質問は、同じシナリオを提示する一連の質問の一部です。...
- 質問142 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールを...
- 質問143 Azure Data Lake StorageGen2の何千ものCSVファイルにデータが保...
- 質問144 Azure Data Lake Storage Gen2 アカウントへのソース データの増...
- 質問145 次の表に示すリソースを含む Azure サブスクリプションがありま...
- 質問146 専用の SQL プールで Twitter フィード データを分析できること...
- 質問147 AzureIoTハブからデータをストリーミングするための異常検出ソリ...
- 質問148 ゲームデータを取得するためのAzureStreamAnalyticsジョブを構築...
- 質問149 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールと...
- 質問150 Pool1 という名前の Azure Synapse Analytics 専用 SQL プールを...
- 質問151 Azure Synapse Analytics 専用の SQL プールにパーティション分...
- 質問152 トランザクションデータの分析ストレージソリューションを設計す
- 質問153 Group1 という名前のセキュリティ グループを含む Azure Active ...
- 質問154 ある企業は、Platform-as-a-Service(PaaS)を使用して新しいデ...
- 質問155 Server1という名前の論理MicrosoftSQLサーバー上にPool1という名...
- 質問156 Azure DatabricksでPySparkを使用して、次のJSON入力を解析しま...
- 質問157 Azure Data Lake StorageGen2アカウントへのアクセスを提供する...
- 質問158 FlightとWeatherという名前の2つのファクトテーブルがあります。...
- 質問159 Azure Data Factory からファイルを出力する必要があります。 出...
- 質問160 Azure Cosmos DB 分析ストアと WS 1 という名前の Azure Synapse...
