説明/参照:
Explanation:
一般的なメタデータの変更には、列をフィーチャとしてマークすることが含まれる場合があります。
参考文献:
https://docs.microsoft.com/ja-jp/azure/machine-learning/studio-module-reference/edit-metadata Testlet 1ケーススタディ概要あなたはプロのスポーツイベントにデータサイエンスを提供する会社のデータ科学者です。 。モデルは、グローバルおよびローカルの市場データを使用して、以下のビジネス目標を達成します。
群衆の反応からの音声に基づいたスポーツイベントでのモバイルデバイスユーザーの気持ちを理解しましょう。

ユーザーが広告に応答する傾向を評価します。
モバイルデバイスに配信される広告のスタイルをカスタマイズします。
ビデオを使用してペナルティイベントを検出する
現在の環境
ペナルティイベントの検出に使用されるメディアは、コンシューマデバイスによって提供されます。メディアに含まれるもの
スポーツイベント中にキャプチャされ、ソーシャルメディアを使用して共有された画像やビデオ。画像とビデオはさまざまなサイズとフォーマットになります。
モデル構築に利用可能なデータは7年間のスポーツイベントメディアで構成されています。スポーツ
イベントメディア記録されたビデオトランスクリプトまたはラジオ解説、およびスポーツイベント中にキャプチャされた関連するソーシャルメディアフィードからのログ。
観客の感情には、イベントの参加者から送信されたオーディオ録音がモノラルとステレオの両方で含まれます
フォーマット
罰則の検出と感情
データ科学者は、違約金を支払うために複数の機械学習モデルを使用してインテリジェントなソリューションを構築する必要があります
イベント検出
データ科学者は、自動機能エンジニアリングを使用してローカル環境でノートブックを作成する必要があります。
機械学習パイプラインにおけるモデル構築
動的なワーカー割り当てを使用してSparkインスタンスを使用して再トレーニングするには、ノートブックをデプロイする必要があります。
ノートブックのソースのみを再コード化するには、新しいSparkインスタンスでノートブックを同じコードで実行する必要があります。
データ。
大域的ペナルティ検出モデルは、実行時に動的ランタイムグラフ計算を使用することによって訓練されなければならない。
トレーニング。
ローカルペナルティ検出モデルはBrainScriptを使用して作成する必要があります。
地域の群衆の感情モデルの実験では、地域のペナルティ検出データを組み合わせる必要があります。
群衆の感情モデルは、歓声や既知のキャッチコピーなどの既知の音を識別する必要があります。
個々の群衆の感情モデルは同様の音を検出します。
ローカルモデルのすべての共有機能は連続変数です。
共有機能は倍精度を使用する必要があります。後続の層は集約移動平均を持たなければなりません
そして利用可能な標準偏差測定基準。
広告
製造の最初の数週間で、次のことが観察されました。
広告レスポンスの評価が低下しました。
ドロップ数が広告スタイル間で一貫していませんでした。
トレーニングデータと本番データ間での機能の分布は一貫していません
分析によると、ユーザーの場所と行動に関する100個の数値機能のうち、位置情報源から取得される47個の機能が未加工の機能として使用されています。偏りと分散の問題を解決するために提案された実験は、10の線形非相関特徴を設計することです。
初期のデータディスカバリーは、群衆のために使用されるトレーニングデータにおける広範囲のターゲット状態密度を示します
感情モデル。
すべてのペナルティ検出モデルは、確率勾配降下法(SGD)を使用した推論フェーズを示しています。
実行が遅すぎます。
音声サンプルによると、キャッチコピーの長さは地域によって25%から47%の間で変化します。
グローバルペナルティ検出モデルの性能は、より低い分散を示すがより高いバイアスを示す。
トレーニングセットと検証セットを比較します。機能の変更を実装する前に、すべてのトレーニングおよび検証ケースを使用してバイアスと差異を確認する必要があります。
広告反応モデルは各イベントの始めに訓練され、スポーツの間に適用されなければなりません
イベント
市場細分化モデルは、同様の広告反応履歴に対して最適化する必要があります。
サンプリングは、ローカルとグローバルのセグメンテーションの間で相互的かつ集団的に排他的に保証されなければならない
同じ機能を共有するモデル。
対応するユーザーの傾向を判断する前に、現地の市場セグメンテーションモデルが適用されます。
広告。
広告反応モデルは、特徴の非線形境界をサポートしなければならない。
広告傾向モデルではカットしきい値が0.45で、加重カッパの偏差が大きいと再トレーニングが行われます。
0.1±5%から。
広告傾向モデルでは、次の図に示すコスト要因を使用しています。

広告傾向モデルでは、次の図に示す提案コスト係数を使用します。
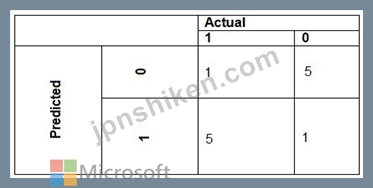
現在および提案されているコスト要因シナリオのパフォーマンス曲線は、次の図に示されています。


