- ホーム
- Microsoft
- AI-102J - Designing and Implementing a Microsoft Azure AI Solution (AI-102日本語版)
- Microsoft.AI-102J.v2025-05-07.q150
- 質問84
有効的なAI-102J問題集はJPNTest.com提供され、AI-102J試験に合格することに役に立ちます!JPNTest.comは今最新AI-102J試験問題集を提供します。JPNTest.com AI-102J試験問題集はもう更新されました。ここでAI-102J問題集のテストエンジンを手に入れます。
AI-102J問題集最新版のアクセス
「425問、30% ディスカウント、特別な割引コード:JPNshiken」
あなたはスマートeコマースプロジェクトを開発しています。
PDFのコンテンツを検索に含めるようにスキルセットを設計する必要があります。
スキルセットの設計図をどのように完成させる必要がありますか?答えるには、適切なサービスを正しいステージにドラッグします。各サービスは、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。

PDFのコンテンツを検索に含めるようにスキルセットを設計する必要があります。
スキルセットの設計図をどのように完成させる必要がありますか?答えるには、適切なサービスを正しいステージにドラッグします。各サービスは、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。
正解:
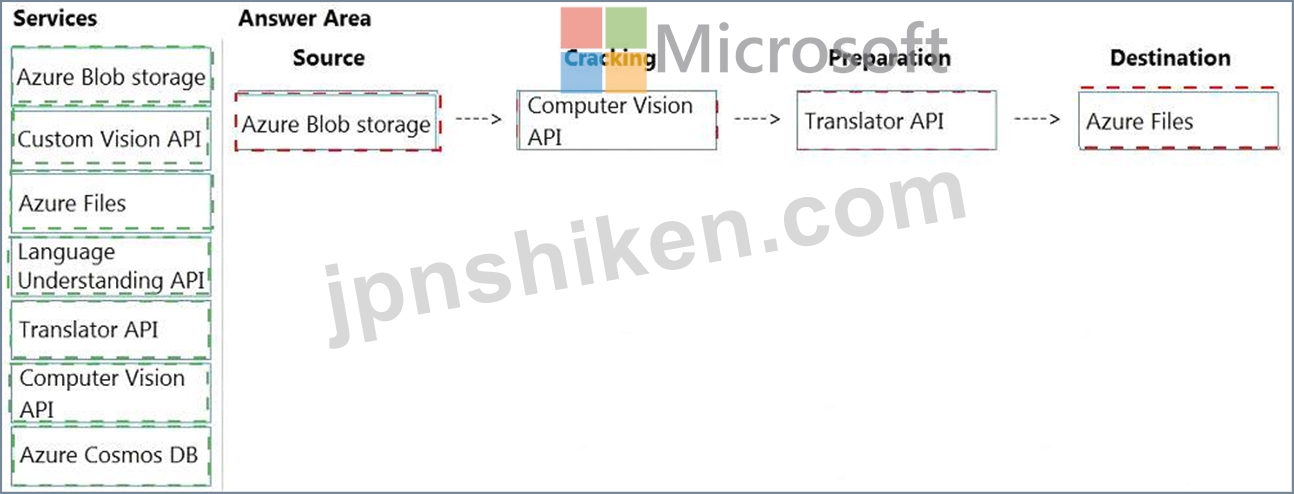
Explanation:

Box 1: Azure Blob storage
At the start of the pipeline, you have unstructured text or non-text content (such as images, scanned documents, or JPEG files). Data must exist in an Azure data storage service that can be accessed by an indexer.
Box 2: Computer Vision API
Scenario: Provide users with the ability to search insight gained from the images, manuals, and videos associated with the products.
The Computer Vision Read API is Azure's latest OCR technology (learn what's new) that extracts printed text (in several languages), handwritten text (English only), digits, and currency symbols from images and multi- page PDF documents.
Box 3: Translator API
Scenario: Product descriptions, transcripts, and all text must be available in English, Spanish, and Portuguese.
Box 4: Azure Files
Scenario: Store all raw insight data that was generated, so the data can be processed later.
Reference:
https://docs.microsoft.com/en-us/azure/search/cognitive-search-concept-intro
https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/overview-ocr

- 質問一覧「150問」
- 質問1 Speech SDK を使用してアプリを構築しています。このアプリは、...
- 質問2 AH という名前の Azure OpenA1 リソースを含む Azure サブスクリ...
- 質問3 Azure portal を使用して、Azure Cognitive Search サービスのイ...
- 質問4 ドキュメント処理ワークフローを開発しています。 財務書類から
- 質問5 URLの配列からナレッジベースを作成するAzureWeblobを構築してい...
- 質問6 プログラムでAzureCognitiveServicesリソースを作成するには、次...
- 質問7 自然言語処理を使用して、ソーシャル メディアでのブランドの認
- 質問8 テスト用のローカルデバイスとオンプレミスのデータセンターで、
- 質問9 次の各ステートメントについて、ステートメントがtrueの場合は、...
- 質問10 Azureサブスクリプションをお持ちの場合 ユーザーのプロンプトに...
- 質問11 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問12 機密文書をスキャンし、言語サービスを使用してコンテンツを分析
- 質問13 次のデータソースがあります。 財務:オンプレミスのMicrosoftSQ...
- 質問14 米国西部のAzureリージョンでホストされているcontoso1という名...
- 質問15 あなたは、公開されているWebサイトからのビデオとテキストを処...
- 質問16 会話型言語理解モデルを構築しています。 モデルが次のサンプル
- 質問17 チャットボットを構築しています。 製品のセットアップ プロセス...
- 質問18 Azure Al Vision クライアント ライブラリを使用するアプリケー...
- 質問19 カスタムビジョンサービスを使用して分類子を作成します。 トレ
- 質問20 ComputerVisionAPIの呼び出しから取得した結果を検証するための...
- 質問21 あなたはテキスト処理ソリューションを開発しています。 以下に
- 質問22 カスタム Azure Al Document Intelligence モデルを使用して契約...
- 質問23 あなたは、テキストを英語からスペイン語に翻訳する App1 という...
- 質問24 ドキュメント処理の要件を満たすために、管理簿記係グループ向け
- 質問25 非リレーショナルデータベースの特徴は何ですか?
- 質問26 半構造化され、ログの発生時に受信されるイベントログデータを保
- 質問27 Azure Al Document Intelligence を使用して医療を分析する App1...
- 質問28 ComputerVisionクライアントライブラリを使用するメソッドを開発...
- 質問29 データ視覚化の2つの用途を食べたのは何ですか?それぞれの正解
- 質問30 AzureCognitiveSearchを使用するエンリッチメントパイプラインを...
- 質問31 ta1 という名前の言語サービス リソースと vnet1 という名前の仮...
- 質問32 あなたはテキスト処理ソリューションを開発しています。 次の方
- 質問33 次の方法を使用して Azure Cognitive Services リソースをプロビ...
- 質問34 次の各ステートメントについて、ステートメントがtrueの場合は、...
- 質問35 TranslatorAPIを使用するアプリケーションのメソッドを開発して...
- 質問36 CS1 という名前の Azure Al Content Safety リソースを含む Azur...
- 質問37 言語翻訳を含むアプリケーションを開発しています。 アプリケー
- 質問38 Azure Al サービスを使用して、音声を英語からフランス語、ドイ...
- 質問39 Microsoft Bot Frameworkを使用して、ローカルコンピューター上...
- 質問40 Azure Al Anomaly Detector サービスを使用する監視ソリューショ...
- 質問41 Microsoft Bot Framework SDK を使用してチャットボットを構築し...
- 質問42 休暇申請に使用されるアプリの会話型インターフェイスを設計して
- 質問43 Anomaly Detector リソースを含む Azure サブスクリプションがあ...
- 質問44 Microsoft Bot Framework Composer を使用して 5 つのボットを作...
- 質問45 ワークロードのタイプを適切なシナリオに一致させます。 答える
- 質問46 あなたの会社には、レポートをページングした植え替えソリューシ
- 質問47 カスタマー サポート チャットボットを構築しています。 以下を...
- 質問48 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問49 Azure Cognitive Search ソリューションと、カテゴリ フィールド...
- 質問50 次の図に示すように、Microsoft Bot Framework コンポーザを使用...
- 質問51 JavaScript でボットを構築します。 Azure コマンド ライン イン...
- 質問52 Form Recognizer を使用して注文書のインデックスを作成する Azu...
- 質問53 予期しないオペレーティングシステムの再起動時にデータベースへ
- 質問54 アプリケーションの言語サービス出力を調べています。 分析され
- 質問55 チャットボットの要件を満たすためにQnAMakerリソースを構築しま...
- 質問56 SO 層に Aldoc1 という名前の Azure Al Document Intelligence ...
- 質問57 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問58 Computer Vision API を使用して画像を分析するアプリがあります...
- 質問59 あなたは製品作成プロジェクトを計画しています。 多言語の製品
- 質問60 Azure OpenAl リソースを含む Azure サブスクリプションがありま...
- 質問61 コンテナにデプロイされるapp1という名前の言語理解アプリケーシ...
- 質問62 過去 24 時間のセンサー データの異常を検出するソリューション...
- 質問63 アプリをデプロイするために使用される Pipeline1 という名前の ...
- 質問64 Azure AI Vision API を使用して画像を分析するアプリを開発して...
- 質問65 AzureCognitiveSearchを使用してナレッジベースを開発しています...
- 質問66 チャットボットのデザインを確認しています。チャットボットには
- 質問67 あなたは英語(イギリス)で行われた講義を記録するサービスを開
- 質問68 チャットボットの音声機能を有効にする必要があります。 実行す
- 質問69 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問70 内部ドキュメントにAzureCognitiveSearchを使用するアプリケーシ...
- 質問71 Azure Al Language でカスタムの質問応答プロジェクトを開発しま...
- 質問72 Face APIを使用して、サンプル画像に基づいて人物の写真を検索す...
- 質問73 ビデオ トレーニング ソリューションのコンテンツを作成していま...
- 質問74 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問75 PDF ファイルとして保存されたプレス リリースのコレクションが...
- 質問76 手書きのアンケート回答をスキャンした画像が 1,000 枚あります...
- 質問77 あなたは外出先での買い物プロジェクトを開発しています。 QnAMa...
- 質問78 あなたはチャットボットを構築しています。 攻撃的で露骨な性的
- 質問79 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問80 Retailドメインを使用して、会社の製品を識別するカスタムビジョ...
- 質問81 CS1 という名前の Azure Al Content Safety リソースを含む Azur...
- 質問82 Azure Stream Analyticsのストリーム処理ジョブでクエリを定義す...
- 質問83 検索 1 という名前の Azure Cognitive Search リソースがあり、...
- 質問84 あなたはスマートeコマースプロジェクトを開発しています。 PDF...
- 質問85 AI1 という名前の Azure OpenAI リソースと User1 という名前の...
- 質問86 ユーザー画像を共有するアプリを構築しています。 ユーザーが画
- 質問87 あなたはボットを構築していて、それは言語理解を使用します。
- 質問88 VideoIndexerサービスを使用して社内会議のビデオを表示するWeb...
- 質問89 モバイルアプリで使用されるカスタムビジョンモデルをトレーニン
- 質問90 A1 GPT 3.5 モデルの 3 つのデプロイをホストする AH という名前...
- 質問91 All という名前の Azure OpenA1 リソースを含む Azure サブスク...
- 質問92 あなたは、テキストを音声に変換するソーシャル メディア拡張機
- 質問93 Azure Cognitive Service for Language リソースを含む Azure サ...
- 質問94 スマート電子商取引プロジェクトを開発しています。 Cognitive S...
- 質問95 Azure Al Video Indexer アカウントを含む Azure サブスクリプシ...
- 質問96 AzureCognitiveSearchを使用してナレッジベースを開発しています...
- 質問97 データウェアハウスの主な目的は何ですか?
- 質問98 ユーザー画像を共有するアプリを構築しています。 次の要件を満
- 質問99 Azure Al コンテンツ セーフティ リソースを含む Azure サブスク...
- 質問100 あなたは知識ベースを開発しています。 Azure Video Analyzer fo...
- 質問101 リレーショナルデータベースの主な特徴は何ですか?
- 質問102 テキストベースのチャットボットがあります。 Content Moderator...
- 質問103 テキストファイル、ビデオ、オーディオストリーム、および仮想デ
- 質問104 あなたは、学生がエッセイの参考文献を見つけるために使用するソ
- 質問105 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問106 あなたは、データ ストリームからの温度データを監視するシステ
- 質問107 Azure OpenAI GPT 3.5 モデルを使用するチャットボットを構築し...
- 質問108 工場の生産ラインで生産されたコンポーネントの障害を認識するア
- 質問109 テキスト入力の意図を識別する Model という名前の Azure Cognit...
- 質問110 Microsoft Bot Framework を使用してボットを構築しています。 ...
- 質問111 Azure Cognitive Service for Language でカスタムの質問応答プ...
- 質問112 既存のAzureCognitiveSearchサービスがあります。 画像やPDFとし...
- 質問113 言語学習ソリューションを構築しています。 次のタスクを実行す
- 質問114 印刷されたフォームを管理するモバイル アプリがあります。 関連...
- 質問115 Windowsサーバー上の共有フォルダーにデータを保存するアプリケ...
- 質問116 チャットボットで使用する会話フローを設計しています。 Microso...
- 質問117 次の構成を持つ Azure サブスクリプションがあります。 * サブス...
- 質問118 Azureサービスをアーキテクチャ内の適切な場所に一致させます。 ...
- 質問119 注: この質問は、同じシナリオを示す一連の質問の一部です。この...
- 質問120 Microsoft Bot Framework SDKを使用して、MicrosoftTeamsチャネ...
- 質問121 Azure Cognitive Search を使用してナレッジベースを開発してい...
- 質問122 あなたはあなたの会社のウェブサイト上の会社のビデオの検索イン
- 質問123 あなたは、食品用の段ボール包装を製造する工場を持っています。
- 質問124 チャットボットがあります。 Bot Framework Emulator を使用して...
- 質問125 次の C# 関数があります。 (Exhibit) 次のコードを使用して関数...
- 質問126 Azure サブスクリプションをお持ちです。 Azure OpenAI モデルを...
- 質問127 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問128 Azure OpenAI Studio を使用してチャットボットを構築します。 ...
- 質問129 Microsoft Bot Framework Composer を使用して、ユーザーがアイ...
- 質問130 予知保全を行う予定です。 100台の産業用機械から1年間IoTセンサ...
- 質問131 音声サンプルをSpeechStudioプロジェクトにアップロードする必要...
- 質問132 FaceAPIへの呼び出しを開発しています。呼び出しは、employeefac...
- 質問133 AH という名前の Azure OpenAI リソースを含む Azure サブスクリ...
- 質問134 Microsoft Bot Framework を使用して構築され、Azure にデプロイ...
- 質問135 インターネットベースのトレーニング ソリューションの構築に成
- 質問136 AM という名前の Azure OpenAI リソースを含む Azure サブスクリ...
- 質問137 Azure Al Speech サービスのテキスト読み上げ機能を使用するアプ...
- 質問138 次の各ステートメントについて、ステートメントがtrueの場合は、...
- 質問139 DM という名前の Azure Al Document Intelligence リソースを含...
- 質問140 言語理解サービスを使用して、Webベースのカスタマーエージェン...
- 質問141 会話型言語理解モデルをトレーニングして、ユーザーの自然言語入
- 質問142 言語理解ポータルを使用して、言語理解モデルを構築します。 次
- 質問143 iOSアプリで使用されるモデルを構築しています。 あなたは猫と犬...
- 質問144 会社の製品のレビューに基づいてワード クラウドを生成するソリ
- 質問145 文を正しく完成させる答えを選択してください。 (Exhibit)...
- 質問146 注:この質問は、同じシナリオを提示する一連の質問の一部です。
- 質問147 CS1 という Azure Al コンテンツ セーフティ リソースを含む Azu...
- 質問148 多言語チャットボットを構築しています。 ポジティブメッセージ
- 質問149 次の方法を使用して、Azure AI サービス リソースをプロビジョニ...
- 質問150 Microsoft Bot Framework SDK を使用してフライト予約ボットを構...
