有効的な70-764J問題集はJPNTest.com提供され、70-764J試験に合格することに役に立ちます!JPNTest.comは今最新70-764J試験問題集を提供します。JPNTest.com 70-764J試験問題集はもう更新されました。ここで70-764J問題集のテストエンジンを手に入れます。
70-764J問題集最新版のアクセス
「452問、30% ディスカウント、特別な割引コード:JPNshiken」
注:この質問は、同じシナリオを使用する一連の質問の一部です。あなたの便宜のために、シナリオは各質問で繰り返されます。各質問はそれぞれ異なる目標と答えの選択を提示しますが、シナリオの本文はこのシリーズの各質問でまったく同じです。
Microsoft Windows 2012 R2を実行するサーバーが5つあります。各サーバーはMicrosoft SQL Serverインスタンスをホストします。環境のトポロジーを以下の図に示します。
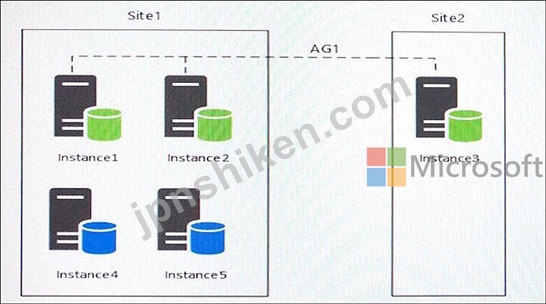
AG1という名前でAlways On Availabilityグループがあります。 AG1の詳細を以下の表に示します。

インスタンス1では、読み書きトラフィックが多く発生します。このインスタンスは、サイズが4テラバイト(TB)のOperationsMainという名前のデータベースをホストします。データベースには複数のデータファイルとファイルグループがあります。ファイルグループの1つはread_onlyであり、データベースの合計サイズの半分です。
Instance4とInstance5はAG1の一部ではありません。インスタンス4は、読み取り/書き込みが多いI / Oを行っています。
Instance5はStagedExternalという名前のデータベースをホストします。夜間のBULK INSERTプロセスは、行ストアのクラスタ化インデックスと2つの非クラスタ化の行ストアインデックスを持つ空のテーブルにデータをロードします。
BULK INSERT操作中のStagedExternalデータベースログファイルの増加を最小限に抑え、BULK INSERTトランザクションの後にポイントインタイムリカバリを実行する必要があります。加えられた変更は、ログバックアップチェーンを中断してはいけません。
Site1とSite2から地理的に離れたデータセンターにInstance6という名前の新しいインスタンスを追加する予定です。 AG1のノード間の待ち時間を最小限に抑える必要があります。
すべてのデータベースは完全復旧モデルを使用しています。すべてのバックアップはネットワークの場所\\ SQLBackup \に書き込まれます。別のプロセスがバックアップをオフサイトの場所にコピーします。データベースの復元に必要な時間とバックアップの保存に必要なスペースの両方を最小限に抑える必要があります。各インスタンスの目標復旧時点(RPO)を次の表に示します。

OperationsMainのフルバックアップを完了するには6時間以上かかります。すべてのSQL ServerバックアップはキーワードCOMPRESSIONを使用します。
以下のソリューションを環境に展開することを計画しています。ソリューションは、AG1の一部であるDB1という名前のデータベースにアクセスします。
* 報告システム:このソリューションは、db_datareaderロールのメンバーであるデータベース・ユーザーにマップされているログインを使用して、DB2内のデータにアクセスします。ユーザーはデータベースに対するEXECUTE権限を持っています。クエリはデータに変更を加えません。クエリは、変数の読み取り専用レプリカに対して負荷分散される必要があります。
* オペレーションシステム:このソリューションは、db_datareaderロールおよびdb_datawriterロールのメンバーであるデータベースユーザーにマップされているログインで、DB1内のデータにアクセスします。ユーザーはデータベースに対するEXECUTE権限を持っています。オペレーションシステムからのクエリは、DDLオペレーションとDMLオペレーションの両方を実行します。
次の表に、インスタンスの待機統計監視要件を示します。

Instance4のバックアップ計画を作成する必要があります。
どのバックアップ計画を作成する必要がありますか?
Microsoft Windows 2012 R2を実行するサーバーが5つあります。各サーバーはMicrosoft SQL Serverインスタンスをホストします。環境のトポロジーを以下の図に示します。
AG1という名前でAlways On Availabilityグループがあります。 AG1の詳細を以下の表に示します。
インスタンス1では、読み書きトラフィックが多く発生します。このインスタンスは、サイズが4テラバイト(TB)のOperationsMainという名前のデータベースをホストします。データベースには複数のデータファイルとファイルグループがあります。ファイルグループの1つはread_onlyであり、データベースの合計サイズの半分です。
Instance4とInstance5はAG1の一部ではありません。インスタンス4は、読み取り/書き込みが多いI / Oを行っています。
Instance5はStagedExternalという名前のデータベースをホストします。夜間のBULK INSERTプロセスは、行ストアのクラスタ化インデックスと2つの非クラスタ化の行ストアインデックスを持つ空のテーブルにデータをロードします。
BULK INSERT操作中のStagedExternalデータベースログファイルの増加を最小限に抑え、BULK INSERTトランザクションの後にポイントインタイムリカバリを実行する必要があります。加えられた変更は、ログバックアップチェーンを中断してはいけません。
Site1とSite2から地理的に離れたデータセンターにInstance6という名前の新しいインスタンスを追加する予定です。 AG1のノード間の待ち時間を最小限に抑える必要があります。
すべてのデータベースは完全復旧モデルを使用しています。すべてのバックアップはネットワークの場所\\ SQLBackup \に書き込まれます。別のプロセスがバックアップをオフサイトの場所にコピーします。データベースの復元に必要な時間とバックアップの保存に必要なスペースの両方を最小限に抑える必要があります。各インスタンスの目標復旧時点(RPO)を次の表に示します。
OperationsMainのフルバックアップを完了するには6時間以上かかります。すべてのSQL ServerバックアップはキーワードCOMPRESSIONを使用します。
以下のソリューションを環境に展開することを計画しています。ソリューションは、AG1の一部であるDB1という名前のデータベースにアクセスします。
* 報告システム:このソリューションは、db_datareaderロールのメンバーであるデータベース・ユーザーにマップされているログインを使用して、DB2内のデータにアクセスします。ユーザーはデータベースに対するEXECUTE権限を持っています。クエリはデータに変更を加えません。クエリは、変数の読み取り専用レプリカに対して負荷分散される必要があります。
* オペレーションシステム:このソリューションは、db_datareaderロールおよびdb_datawriterロールのメンバーであるデータベースユーザーにマップされているログインで、DB1内のデータにアクセスします。ユーザーはデータベースに対するEXECUTE権限を持っています。オペレーションシステムからのクエリは、DDLオペレーションとDMLオペレーションの両方を実行します。
次の表に、インスタンスの待機統計監視要件を示します。
Instance4のバックアップ計画を作成する必要があります。
どのバックアップ計画を作成する必要がありますか?

