- ホーム
- Microsoft
- 70-764 - Administering a SQL Database Infrastructure
- Microsoft.70-764.v2019-07-23.q247
- 質問190
有効的な70-764問題集はJPNTest.com提供され、70-764試験に合格することに役に立ちます!JPNTest.comは今最新70-764試験問題集を提供します。JPNTest.com 70-764試験問題集はもう更新されました。ここで70-764問題集のテストエンジンを手に入れます。
70-764問題集最新版のアクセス
「452問、30% ディスカウント、特別な割引コード:JPNshiken」
注:この質問は同じシナリオを使用する一連の質問の一部です。あなたのための
便宜上、シナリオは各質問で繰り返されます。それぞれの質問は異なる目標を提示します
しかし、シナリオのテキストは、このシリーズの各質問でまったく同じです。
繰り返しシナリオの開始
Microsoft Windows 2012 R2を実行するサーバーが5つあります。各サーバーはMicrosoft SQL Serverをホストします。
インスタンス。環境のトポロジーを以下の図に示します。
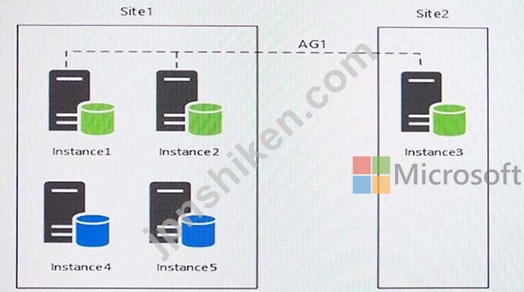
AG1という名前でAlways On Availabilityグループがあります。 AG1の詳細は以下の通りです。
表。

インスタンス1では、読み書きトラフィックが多く発生します。インスタンスは、OperationsMainという名前のデータベースをホストしています。
サイズは4TBです。データベースには複数のデータファイルとファイルグループがあります。ファイルグループの一つは、
read_onlyで、データベースの合計サイズの半分です。
Instance4とInstance5はAG1の一部ではありません。インスタンス4は、大量の読み書きI / Oを行っています。
Instance5はStagedExternalという名前のデータベースをホストします。毎晩のBULK INSERTプロセスは、データを
行ストアクラスタ化インデックスと2つの非クラスタ化行ストアインデックスを持つ空のテーブル。
BULK INSERT中はStagedExternalデータベースログファイルの増加を最小限に抑える必要があります。
BULK INSERTトランザクションの後に操作を実行し、ポイントインタイムリカバリを実行します。行わなければならない変更
ログバックアップチェーンを中断しないでください。
Site1から地理的に離れたデータセンターにInstance6という名前の新しいインスタンスを追加する予定です。
とサイト2。 AG1のノード間の待ち時間を最小限に抑える必要があります。
すべてのデータベースは完全復旧モデルを使用しています。すべてのバックアップはネットワークの場所\\ SQLBackup \に書き込まれます。 A
別のプロセスがバックアップをオフサイトの場所にコピーします。両方の時間を最小限に抑える必要があります。
データベースとバックアップの保存に必要なスペースを復元します。の目標復旧時点(RPO)
各インスタンスを次の表に示します。
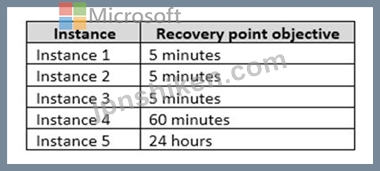
OperationsMainのフルバックアップを完了するには6時間以上かかります。すべてのSQL Serverバックアップは、
キーワード圧縮。
以下のソリューションを環境に展開することを計画しています。ソリューションは、というデータベースにアクセスします。
AG1の一部であるDB1。
報告システム:このソリューションは、データベースユーザーにマップされたログインを使用してDB1のデータにアクセスします。

これはdb_datareaderロールのメンバーです。ユーザーはデータベースに対するEXECUTE権限を持っています。
クエリによってデータが変更されることはありません。クエリは、変数の読み取り専用に対して負荷分散される必要があります。
レプリカ。
オペレーションシステム:このソリューションは、データベースユーザーにマップされているログインで、DB1のデータにアクセスします。
それはdb_datareaderロールとdb_datawriterロールのメンバーです。ユーザーはEXECUTE権限を持っています
データベース上。オペレーションシステムからのクエリは、DDLオペレーションとDMLオペレーションの両方を実行します。
次の表に、インスタンスの待機統計監視要件を示します。

繰り返しのシナリオが終了しました。
Instance4のバックアップ計画を作成する必要があります。
どのバックアップ計画を作成する必要がありますか?
便宜上、シナリオは各質問で繰り返されます。それぞれの質問は異なる目標を提示します
しかし、シナリオのテキストは、このシリーズの各質問でまったく同じです。
繰り返しシナリオの開始
Microsoft Windows 2012 R2を実行するサーバーが5つあります。各サーバーはMicrosoft SQL Serverをホストします。
インスタンス。環境のトポロジーを以下の図に示します。
AG1という名前でAlways On Availabilityグループがあります。 AG1の詳細は以下の通りです。
表。
インスタンス1では、読み書きトラフィックが多く発生します。インスタンスは、OperationsMainという名前のデータベースをホストしています。
サイズは4TBです。データベースには複数のデータファイルとファイルグループがあります。ファイルグループの一つは、
read_onlyで、データベースの合計サイズの半分です。
Instance4とInstance5はAG1の一部ではありません。インスタンス4は、大量の読み書きI / Oを行っています。
Instance5はStagedExternalという名前のデータベースをホストします。毎晩のBULK INSERTプロセスは、データを
行ストアクラスタ化インデックスと2つの非クラスタ化行ストアインデックスを持つ空のテーブル。
BULK INSERT中はStagedExternalデータベースログファイルの増加を最小限に抑える必要があります。
BULK INSERTトランザクションの後に操作を実行し、ポイントインタイムリカバリを実行します。行わなければならない変更
ログバックアップチェーンを中断しないでください。
Site1から地理的に離れたデータセンターにInstance6という名前の新しいインスタンスを追加する予定です。
とサイト2。 AG1のノード間の待ち時間を最小限に抑える必要があります。
すべてのデータベースは完全復旧モデルを使用しています。すべてのバックアップはネットワークの場所\\ SQLBackup \に書き込まれます。 A
別のプロセスがバックアップをオフサイトの場所にコピーします。両方の時間を最小限に抑える必要があります。
データベースとバックアップの保存に必要なスペースを復元します。の目標復旧時点(RPO)
各インスタンスを次の表に示します。
OperationsMainのフルバックアップを完了するには6時間以上かかります。すべてのSQL Serverバックアップは、
キーワード圧縮。
以下のソリューションを環境に展開することを計画しています。ソリューションは、というデータベースにアクセスします。
AG1の一部であるDB1。
報告システム:このソリューションは、データベースユーザーにマップされたログインを使用してDB1のデータにアクセスします。
これはdb_datareaderロールのメンバーです。ユーザーはデータベースに対するEXECUTE権限を持っています。
クエリによってデータが変更されることはありません。クエリは、変数の読み取り専用に対して負荷分散される必要があります。
レプリカ。
オペレーションシステム:このソリューションは、データベースユーザーにマップされているログインで、DB1のデータにアクセスします。
それはdb_datareaderロールとdb_datawriterロールのメンバーです。ユーザーはEXECUTE権限を持っています
データベース上。オペレーションシステムからのクエリは、DDLオペレーションとDMLオペレーションの両方を実行します。
次の表に、インスタンスの待機統計監視要件を示します。
繰り返しのシナリオが終了しました。
Instance4のバックアップ計画を作成する必要があります。
どのバックアップ計画を作成する必要がありますか?
正解:A
説明/参照:
Explanation:
シナリオ:インスタンス4は、読み取り/書き込みが多いI / Oを行っています。 Instance4の目標復旧時点は60です。
分
Explanation:
シナリオ:インスタンス4は、読み取り/書き込みが多いI / Oを行っています。 Instance4の目標復旧時点は60です。
分

- 質問一覧「247問」
- 質問1 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問2 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問3 SQL Serverのディスク使用量監視の要件に対処する必要があります...
- 質問4 あなたの会社はシアトルとモントリオールにオフィスがあります。
- 質問5 次のサーバーがあります。 (Exhibit) SQL1はDB1という名前のデー...
- 質問6 64コアを使用するMicrosoft SQL Server 2016 Enterprise Edition...
- 質問7 Contosoという名前のMicrosoft SQL Server 2016データベースをSe...
- 質問8 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問9 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問10 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問11 Management Data Warehouseインスタンスを作成してデータ収集を...
- 質問12 Contosoという名前のMicrosoft SQL Server 2016データベースをSe...
- 質問13 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問14 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問15 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問16 製造データベースの復旧要件を満たすソリューションを推奨する必
- 質問17 Microsoft SQL Server 2012インスタンスを管理します。 FILETABL...
- 質問18 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問19 2つのプロセッサを搭載したServer1という名前のサーバーがありま...
- 質問20 SQL Server 2014を使用してデータベースを展開します。 データベ...
- 質問21 注文処理システム用にWindows Azure SQL Databaseを設計していま...
- 質問22 レポートダッシュボードで使用されているクエリがあります。ユー
- 質問23 DB1という名前のデータベースがあります。 3つの異なるテーブル...
- 質問24 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問25 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問26 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問27 総括 あなたはFairstoneという製造会社の上級データベース管理者...
- 質問28 Webホスティング会社にMicrosoft SQL Server 2016をインストール...
- 質問29 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問30 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問31 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問32 トランザクションデータベースとレポートをホストするMicrosoft ...
- 質問33 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問34 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問35 Microsoft SQL Server 2016を新しいサーバーにインストールしま...
- 質問36 Microsoft SQL Server 2016インスタンスをインストールする予定...
- 質問37 あなたの会社はシアトルとモントリオールにオフィスがあります。
- 質問38 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問39 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問40 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問41 SQL Server 2012 R2でホストされているデータベースがあります。...
- 質問42 会社は、クレジットカード番号を含む顧客データをMicrosoft SQL ...
- 質問43 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問44 OrderDetailという名前のテーブルを含むMicrosoft SQL Server 20...
- 質問45 Microsoft SQL Server 2016インスタンスを管理します。 他のプロ...
- 質問46 SQL1という名前のSQL Server 2014インスタンスがあります。 SQL1...
- 質問47 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問48 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問49 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問50 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問51 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問52 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問53 Microsoft SQL Server 2016インスタンスを管理します。インスタ...
- 質問54 16個のプロセッサを搭載したServer1という名前のサーバーがあり...
- 質問55 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問56 Contosoという名前のMicrosoft SQL Server 2016データベースをSe...
- 質問57 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問58 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問59 あなたはABC.comで開発者として働いています。 すべてのデータベ...
- 質問60 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問61 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問62 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問63 自社のアプリケーションで使用されるデータを管理するためにSQL ...
- 質問64 クエリを実行するアプリケーションをトラブルシューティングして
- 質問65 SQL Server 2014を使用するSQLProdという名前のSQL Serverインス...
- 質問66 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問67 Microsoft SQL Server 2016の既定のインスタンスを含む単一のサ...
- 質問68 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問69 SQL Server 2014のインスタンスを管理します。 ユーザーは、SQL ...
- 質問70 Microsoft SQL Server環境を管理します。バックアップを作成する...
- 質問71 組織の販売取引を記録するSaleshistoryという名前のデータベース...
- 質問72 SQL Server 2014がインストールされているサーバーがあります。 ...
- 質問73 SQLDevとSQLProdという2つのSQL Serverインスタンスがあり、さま...
- 質問74 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問75 Ordersという名前のMicrosoft SQL Server 2016データベースを管...
- 質問76 データベースをサーバー間で移動する必要があります。 あなたは
- 質問77 4台のサーバーを含むSQL Server 2014環境があります。 サーバー...
- 質問78 Salesという名前のMicrosoft SQL Serverデータベースを管理しま...
- 質問79 Contosoという名前のMicrosoft SQL Server 2016データベースをSe...
- 質問80 DB1という名前のデータベースを持つMicrosoft SQL Serverインス...
- 質問81 データベースを照会するアプリケーションがあります。ユーザーは
- 質問82 あなたは過去6ヶ月間に成長したテーブルを持っています。 ユーザ...
- 質問83 IT部門と製造部門のユーザーグループを最低限提供する必要があり...
- 質問84 DB1という名前のデータベースを設計しています。 変更は毎週水曜...
- 質問85 次のMicrosoft SQL Serverインスタンスがあります。 (Exhibit) S...
- 質問86 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問87 Microsoft SQL Server 2016データベースを管理します。 データベ...
- 質問88 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問89 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問90 アプリケーションを操作しているユーザーに関係なく、OLTPデータ...
- 質問91 DB1という名前のSQL Server 2012データベースがあります。 SQL A...
- 質問92 Salesスキーマに複数のテーブルがあるMicrosoft SQL Server 2016...
- 質問93 あなたは組織のデータベース管理者です。あなたは人間のメンバー
- 質問94 SQL1という名前のSQL Server 2014サーバーがあります。あなたは...
- 質問95 顧客分類に関するSales Directorの要件に対処する必要があります...
- 質問96 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問97 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問98 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問99 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問100 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問101 同じサーバー上に2つのデータベースDB1とDB2があります。 DB1にS...
- 質問102 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問103 アプリケーションのユーザー名とクレジットカード番号を保存する
- 質問104 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問105 電子商取引アプリケーションで使用されるデータを格納するために
- 質問106 10台のMicrosoft SQL Server 2016サーバーがあります。 DW1とい...
- 質問107 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問108 ストアドプロシージャ内のINSERTステートメントが失敗した場合、...
- 質問109 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問110 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問111 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問112 でホストされている金融データベースを含むMicrosoft SQL Server...
- 質問113 あなたはSQL Server 2014インスタンスの新しいデータベース管理...
- 質問114 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問115 Microsoft SQL Server 2016データベースを管理します。 データベ...
- 質問116 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問117 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問118 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問119 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問120 運送会社の情報を格納するデータベースがあります。という名前の
- 質問121 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問122 Microsoft SQL Server 2016の2つのインスタンスを管理します。 ...
- 質問123 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問124 オンプレミスのMicrosoft SQL Server環境とMicrosoft Azureを統...
- 質問125 データベースをazureに移行する予定です。 すべてのオブジェクト...
- 質問126 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問127 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問128 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問129 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問130 新しいSQL Server 2014インスタンス用の監視アプリケーションを...
- 質問131 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問132 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問133 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問134 ある企業がオンプレミスのMicrosoft SQL Server環境とMicrosoft ...
- 質問135 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問136 2台のMicrosoft SQL Server 2012サーバーを管理します。 各サー...
- 質問137 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問138 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問139 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問140 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問141 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問142 Microsoft SQL Server 2016インスタンスをインストールします。 ...
- 質問143 5台のサーバーにわたって同じSQL Server 2016インストール構成を...
- 質問144 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問145 Microsoft SQL Server環境を管理します。データベースメールを設...
- 質問146 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問147 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問148 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問149 非パーティション表を持つDB1という名前のデータベースを保守し...
- 質問150 Microsoft SQL Server 2016サーバーを管理します。 新しい機能を...
- 質問151 Microsoft SQL Server 2016サーバーを管理します。 サーバー上の...
- 質問152 あなたはあなたの会社でMicrosoft SQL Server 2016のすべての展...
- 質問153 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問154 非パーティション表を持つDB1という名前のデータベースを保守し...
- 質問155 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問156 Microsoft SQL Server 2016データベースを管理します。 サービス...
- 質問157 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問158 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問159 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問160 DB1という名前のMicrosoft SQL Serverデータベースがあります。 ...
- 質問161 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問162 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問163 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問164 データベースサーバーは高度なセキュリティ環境で管理します。あ
- 質問165 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問166 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問167 完全復旧モデルを使用するように構成されたDB1という名前のデー...
- 質問168 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問169 2つの異なるホストでホストされているSVR1とSVR2という名前のMic...
- 質問170 総括 あなたは、Leafieldという名前のソフトウェア開発会社の上...
- 質問171 20台のサーバーを含むSQL Server 2014環境があります。 企業セキ...
- 質問172 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問173 Human_Resourcesという名前のWindows Azure SQL Databaseデータ...
- 質問174 Microsoft SQL Server環境を管理します。バックアップを作成する...
- 質問175 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問176 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問177 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問178 運送会社の情報を格納するデータベースがあります。という名前の
- 質問179 Microsoft SQL Serverデータベース用のフォールトトレランスソリ...
- 質問180 データベースを照会するアプリケーションがあります。 ユーザー
- 質問181 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問182 Microsoft SQL Server 2016インスタンスを管理します。 SQLエー...
- 質問183 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問184 あなたはABC.comという会社のデータベース管理者(DBA)として働...
- 質問185 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問186 DB1という名前のMicrosoft SQL Serverデータベースを保守します...
- 質問187 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問188 Microsoft SQL Server 2016データベースを管理します。 トランザ...
- 質問189 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問190 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問191 Microsoft SQL Server環境を管理します。データベースメールを設...
- 質問192 あなたの会社はSQL Azureサブスクリプションを持っています。 Da...
- 質問193 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問194 HA / Server01およびHA / Server02という名前のレプリカを持つ可...
- 質問195 あなたはContoso、Ltdのデータベース管理者です。MicrosoftSQL S...
- 質問196 DB1という名前のMicrosoft SQL Serverデータベースには、FG1とFG...
- 質問197 注:この質問は同じシナリオを使用する一連の質問の一部です。あ
- 質問198 という名前のSQLログインを使用してAgentPortalデータベースに接...
- 質問199 単一のユーザー定義を含むContosoという名前のMicrosoft SQL Ser...
- 質問200 Microsoft SQL Server 2016サーバーを管理します。 トランザクシ...
- 質問201 複数のデータベースを持つMicrosoft SQL Server 2016インスタン...
- 質問202 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問203 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問204 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問205 SQL Server 2016データベースインスタンスを管理します。 フェー...
- 質問206 概要 総括 ADatum Corporationはマイアミとモントリオールにオフ...
- 質問207 あなたはオンライントランザクションのデータを保存するSQL Serv...
- 質問208 SQL1とSQL2という名前の2つのサーバーでログ配布を構成し、スタ...
- 質問209 DB1という名前のデータベースがあります。 ユーザーは、DB1のデ...
- 質問210 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問211 Always On可用性グループに展開されている複数のMicrosoft SQL S...
- 質問212 Contosoという名前のMicrosoft SQL Server 2016データベースをSe...
- 質問213 ETL専用のサーバーを展開することを計画しています(抽出、変換...
- 質問214 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問215 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問216 保存されているデータベースを含む、Inventoryという名前のWindo...
- 質問217 複数のSQL Serverエージェントジョブが構成されているMicrosoft ...
- 質問218 Microsoft SQL Server 2016サーバーを管理します。 MSSQLSERVER...
- 質問219 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問220 データベースを作成する予定です。 データベースは、2日間続く特...
- 質問221 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問222 dbo.Logという名前のテーブルを含むMicrosoft SQL Server 2016デ...
- 質問223 SQL Azureデータベース用のストアドプロシージャを構築していま...
- 質問224 概要 あなたはLitware、Incという会社のデータベース管理者です...
- 質問225 トランザクションデータベースとレポートをホストするMicrosoft ...
- 質問226 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問227 Microsoft SQL Server 2016データベースを管理します。 データベ...
- 質問228 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問229 TrustworthyがOnに設定されているMicrosoft SQL Server 2016デー...
- 質問230 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問231 データベースを作成する予定です。 データベースは、2日間続く特...
- 質問232 Server01 / HA、Server02 / HAという名前のレプリカを持つHaCont...
- 質問233 特定のインスタンス宛てのセッション要求が可能になるように、ど
- 質問234 DB1という名前のSQL Server 2012データベースがあります。 Devic...
- 質問235 トランザクションデータベースとレポートをホストするMicrosoft ...
- 質問236 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問237 特定のインスタンス宛てのセッション要求が可能になるように、ど
- 質問238 SQL Server 2016 5ノードフェールオーバークラスターを実装して...
- 質問239 あなたは、Microsoft SQL Server 2016インスタンスのデータベー...
- 質問240 クエリを実行するアプリケーションをトラブルシューティングして
- 質問241 注:この質問は同じシナリオを提示する一連の質問の一部です。各
- 質問242 概要 アプリケーション概要 Contoso、Ltd.は、エンタープライズ...
- 質問243 バックグラウンド 企業情報 Fabrikam、Inc.は、インターネット上...
- 質問244 自動的に開始するようにMicrosoft SQL Serverエージェントサービ...
- 質問245 注:この質問は、同じまたは類似の回答の選択肢を使用する一連の
- 質問246 あなたはABC.comでデータベース管理者(DBA)として働いています...
- 質問247 注:この質問は同じシナリオを提示する一連の質問の一部です。各
